graph TD
A["THE QUESTION: Does education cause higher earnings?"]
B["SIMPLE OLS: Naive regression shows about 7% return"]
C["THE PROBLEM: Ability bias and omitted variables inflate the estimate"]
D["MULTIPLE REGRESSION: Adding controls helps but cannot fix unobservables"]
E["QUASI-EXPERIMENTS: IV with twins, QOB, and child labor laws"]
F["RD: Sheepskin effect tests diploma vs. learning"]
G["DD: Policy changes provide before-and-after comparisons"]
A --> B --> C --> D --> E --> F --> G
style A fill:#3498db,color:#fff
style B fill:#2c3e50,color:#fff
style C fill:#c0392b,color:#fff
style D fill:#e67e22,color:#fff
style E fill:#8e44ad,color:#fff
style F fill:#2d8659,color:#fff
style G fill:#2d8659,color:#fff
linkStyle 0,1,2,3,4,5 stroke:#888,stroke-width:2px
6. The Wages of Schooling

![]()
![]()
TipLearning Objectives
By the end of this chapter, you will be able to:
- Estimate the simple OLS return to schooling and explain why it may overstate the causal effect
- Apply the omitted variables bias (OVB) formula to predict the direction of bias from unobserved ability
- Explain why randomized experiments are the gold standard but infeasible for schooling
- Use twin fixed effects to control for shared family and genetic factors
- Understand how measurement error creates attenuation bias, especially in differenced data
- Apply instrumental variables (quarter of birth, twin’s report, compulsory schooling laws) to education
- Use regression discontinuity to test for sheepskin (diploma) effects
- Illustrate how differences-in-differences exploits policy changes to estimate causal returns
- Compare estimates across all five methods and assess what the true return to schooling is
This chapter is unique. It applies all five methods from the book — regression, RCTs, IV, RD, and DD — to a single question: does education really cause higher earnings? When different methods agree, we gain confidence. When they disagree, we learn what each method can and cannot do. The chapter builds a methods ladder, starting from the simplest approach and climbing to the most sophisticated, with each step motivated by a limitation of the previous one.
Key Concepts and Definitions
Ability Bias: The upward bias in OLS estimates of the return to schooling caused by the omission of innate ability. More able people get more education AND earn more, inflating the apparent effect of schooling.
TipExample
A simple regression shows each year of schooling raises earnings by 7%, but part of this reflects the fact that high-IQ individuals stay in school longer and would earn more regardless.
NoteAnalogy
Like attributing a swimmer’s speed entirely to their swimsuit. Faster swimmers tend to buy better suits, so the suit gets credit for speed that was really due to talent.
Twin Fixed Effects: A strategy that compares outcomes within pairs of identical twins who differ in their education levels. Because twins share genes and family background, differencing eliminates these shared confounders.
TipExample
If one twin has 16 years of schooling and earns $60,000 while the other twin has 14 years and earns $54,000, the within-pair return is ($6,000 / 2 years) = $3,000 per year.
NoteAnalogy
Like comparing two identical seeds planted in the same soil and climate, but one gets extra fertilizer. Any difference in growth must be due to the fertilizer, since everything else is shared.
Within-Pair Differences: The technique of subtracting one twin’s outcome from the other’s to eliminate all shared characteristics. This transforms the data from levels (how much each twin earns) to differences (how much MORE one twin earns than the other).
TipExample
\(\Delta Y_f = Y_{twin1} - Y_{twin2}\) and \(\Delta S_f = S_{twin1} - S_{twin2}\). Regressing the wage difference on the schooling difference gives the within-pair return.
NoteAnalogy
Like measuring the height difference between two siblings rather than their individual heights. The difference removes the family’s genetic baseline and isolates the effect of what differed between them.
Measurement Error: Imprecision in the recording of a variable, where reported values differ from true values due to misreporting, rounding, or recall mistakes. In regression, measurement error in the explanatory variable biases the coefficient toward zero.
TipExample
Twins asked to report their years of education may misremember by a year. This noise dilutes the true variation in schooling and biases the return estimate downward.
NoteAnalogy
Like trying to read a ruler through foggy glasses. The markings are there, but the fog (measurement error) makes it hard to read them precisely, leading you to underestimate the true length.
Signal-to-Noise Ratio: The proportion of the total variation in a variable that reflects true variation (signal) versus measurement error (noise). A low signal-to-noise ratio causes severe attenuation bias.
TipExample
If true within-twin schooling variation is 1 year but measurement error adds 2 years of noise, the signal-to-noise ratio is low and the twin FE estimate is badly attenuated.
NoteAnalogy
Like trying to hear a whisper in a noisy stadium. The whisper (signal) is real, but the crowd noise overwhelms it. In a quiet room, the same whisper is perfectly clear.
Reliability Ratio: The fraction of the total variance of a variable that is true variance (as opposed to error variance). A reliability ratio of 0.5 means that attenuation bias cuts the coefficient in half.
TipExample
If self-reported education has a reliability ratio of 0.85, the OLS coefficient is biased toward zero by about 15%. In differenced twin data, the reliability ratio can drop to 0.5, doubling the bias.
NoteAnalogy
Like a scale that is accurate 85% of the time and gives random readings 15% of the time. The more unreliable the scale, the less you can trust its average reading.
Sheepskin Effect: The additional earnings boost associated with completing a degree (earning the diploma) beyond the year-by-year return to education. Named after the sheepskin diplomas were once printed on.
TipExample
If each year of college raises earnings by 7%, but graduating (year 4 specifically) adds an extra 15% jump, the 15% jump is the sheepskin effect — the value of the credential itself.
NoteAnalogy
Like a loyalty card that gives a free coffee after every 10 purchases. The first 9 stamps (years of schooling) are valuable, but the 10th stamp (the degree) unlocks a bonus reward.
Human Capital Theory: The view that education raises earnings by building productive skills, knowledge, and abilities that make workers more valuable to employers.
TipExample
An engineering student learns calculus, physics, and design — skills that directly increase her productivity and justify higher pay.
NoteAnalogy
Like sharpening a knife. More education makes the worker a better tool, and employers pay more for a sharper blade.
Signaling Theory: The view that education raises earnings not by increasing skills but by revealing pre-existing ability to employers. The degree serves as a signal that the holder is talented and hardworking.
TipExample
An employer who cannot directly observe a job candidate’s ability uses a college degree as evidence that the candidate is smart and disciplined enough to complete four years of coursework.
NoteAnalogy
Like a peacock’s tail. The tail does not make the peacock a better flyer — it signals genetic fitness to potential mates. Similarly, a degree may not make you more productive; it signals that you were productive to begin with.
Credential Effect: The earnings premium attributable specifically to holding a diploma or credential, as opposed to the knowledge gained year by year. It is the empirical counterpart of the sheepskin effect.
TipExample
Clark and Martorell’s RD study found that the Texas high school diploma had almost no credential effect — students just above and below the exam cutoff had similar earnings.
NoteAnalogy
Like a name-brand label on a generic product. The credential effect asks: does the label itself add value, or is it what is inside the box that matters?
Heterogeneous Treatment Effects: The idea that the causal effect of treatment varies across individuals or subgroups, rather than being a single number that applies to everyone.
TipExample
The return to schooling may be 12% for low-income students but only 5% for high-income students, because education opens doors that were already open for the wealthy.
NoteAnalogy
Like the effect of an umbrella on staying dry. In a light drizzle, the umbrella is barely needed. In a downpour, it is essential. The same treatment has different effects depending on the circumstances.
Convergence of Evidence: The principle that when multiple methods — each with different assumptions, data, and potential biases — all point to similar conclusions, we gain much stronger confidence in the finding than any single method can provide.
TipExample
OLS, twin FE, twin IV, quarter-of-birth IV, child labor law IV, and DD all estimate the return to schooling at roughly 7–10% per year. No single estimate is definitive, but their agreement is powerful.
NoteAnalogy
Like multiple witnesses to an event all telling the same story from different vantage points. One witness might be mistaken, but if five independent witnesses agree, the story is probably true.
Return to Schooling: The percentage increase in earnings caused by one additional year of education. It is the central parameter this chapter seeks to estimate using multiple methods.
TipExample
A return of 8% means that one extra year of school causes earnings to increase by 8%, holding all else equal. Over a career, this compounds to a substantial difference.
NoteAnalogy
Like the interest rate on a savings account. Each “deposit” (year of school) earns a return that accumulates over time. An 8% return per year of schooling is a very high-yield investment.
Quarter-of-Birth Instrument: An instrument for years of schooling based on the quarter of the year in which a person was born. Because school entry and compulsory attendance laws interact with birth timing, children born in different quarters accumulate different amounts of schooling.
TipExample
Children born in Q4 start school slightly younger and must stay longer before reaching the legal dropout age, accumulating about 0.1 extra years of schooling on average.
NoteAnalogy
Like a relay race where some runners start a few steps ahead because of where they line up. The starting position (birth quarter) is essentially random but determines how far they run (years of schooling) before they can step off the track (drop out).
Compulsory Schooling Laws: Government regulations that require children to attend school until a specified minimum age (e.g., 16). These laws create exogenous variation in schooling by forcing some students to stay in school longer than they otherwise would.
TipExample
A state that raises its minimum school-leaving age from 14 to 16 compels students who would have dropped out at 14 to stay two more years — generating variation that is independent of ability.
NoteAnalogy
Like a mandatory seatbelt law. Some people would buckle up anyway (always-takers), but the law forces additional compliance from people who would not have done it voluntarily — and it is these marginal compliers whose outcomes we can study.
Endogenous Variable: A variable in a regression whose value is determined inside the system being studied, meaning it is correlated with the error term. OLS estimates involving endogenous variables are biased because the variable is not “as good as randomly assigned.”
TipExample
Years of schooling is endogenous in an earnings regression because unobserved ability affects both schooling and earnings simultaneously.
NoteAnalogy
Like the chicken-and-egg problem. Did the variable cause the outcome, or did they both arise from a common underlying factor? When cause and effect are tangled together, you cannot simply read off the causal relationship.
The Earnings-Education Gradient
College graduates earn roughly twice as much as high school graduates. But how much of that gap reflects the causal effect of education, and how much reflects the fact that people who go to college were going to earn more anyway?
Let’s start with the simplest possible approach: regress earnings on schooling with no controls. This is the bivariate regression:
\[\ln W_i = \alpha + \rho \, S_i + e_i\]
where:
- \(\ln W_i\) = log weekly earnings for individual \(i\) (
lnw) - \(S_i\) = years of schooling (
s) - \(\rho\) = the return to schooling — the percentage increase in earnings per additional year of education
- \(e_i\) = residual (includes ability, motivation, family background, and everything else we cannot observe)
Because \(\ln W\) is the outcome, the coefficient \(\rho\) has a convenient interpretation: a value of 0.07 means each year of schooling is associated with approximately 7% higher earnings.
Code
# Load clean quarter-of-birth data (Angrist & Krueger 1991, 329k men born 1930-1939)
import pandas as pd
import numpy as np
import pyfixest as pf
# (IV handled by pf.feols with pipe syntax)
GITHUB_DATA_URL = "https://raw.githubusercontent.com/cmg777/intro2causal/main/data/"
qob = pd.read_csv(GITHUB_DATA_URL + "ch6/qob_clean.csv")
qob.head(3)| lnw | s | qob | yob | q1 | q2 | q3 | q4 | age | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 5.790019 | 12.0 | 1 | 30 | 1 | 0 | 0 | 0 | 50.0 |
| 1 | 5.952494 | 11.0 | 1 | 30 | 1 | 0 | 0 | 0 | 50.0 |
| 2 | 5.315949 | 12.0 | 1 | 30 | 1 | 0 | 0 | 0 | 50.0 |
Code
# Bivariate OLS: the simplest possible regression
bivariate = pf.feols("lnw ~ s", data=qob, vcov="hetero")
# Display results
pd.DataFrame({
"Variable": bivariate.coef().index,
"Coefficient": bivariate.coef().round(4).values,
"Std. Error": bivariate.se().round(4).values,
"t-statistic": bivariate.tstat().round(2).values,
"p-value": bivariate.pvalue().round(3).values,
})| Variable | Coefficient | Std. Error | t-statistic | p-value | |
|---|---|---|---|---|---|
| 0 | Intercept | 4.9952 | 0.0051 | 984.49 | 0.0 |
| 1 | s | 0.0709 | 0.0004 | 185.95 | 0.0 |
Each additional year of schooling is associated with about 7% higher weekly earnings. With 329,000 observations, the estimate is extremely precise.
Code
import matplotlib.pyplot as plt
# Compute mean earnings by schooling level
binned = qob.groupby("s")["lnw"].mean().reset_index()
fig, ax = plt.subplots(figsize=(8, 5))
ax.scatter(binned["s"], binned["lnw"], color="black", s=40, zorder=5)
ax.plot(binned["s"], binned["lnw"], "k-", alpha=0.4)
ax.set_xlabel("Years of Schooling")
ax.set_ylabel("Mean Log Weekly Earnings")
ax.set_title("The Earnings-Education Gradient")
plt.tight_layout()
plt.show()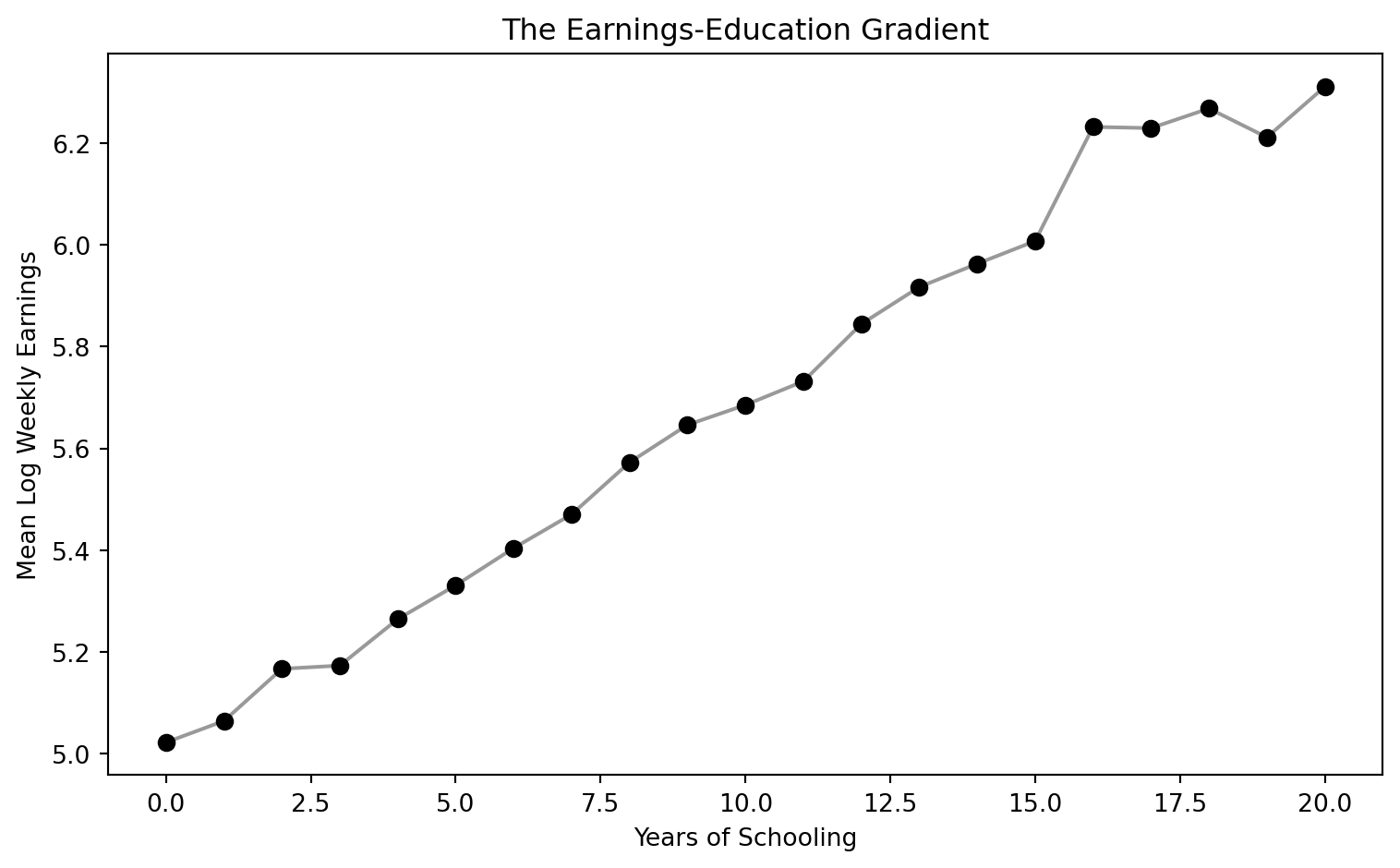
But is this causal? This is the ability bias problem. Smarter people stay in school longer AND earn more — both independently. If we don’t account for ability, OLS overstates the true causal return.
\[\hat{\rho}_{OLS} = \rho + \underbrace{\text{Ability bias}}_{\text{likely positive}}\]
where \(\rho\) is the true causal return to schooling and \(\hat{\rho}_{OLS}\) is the OLS estimate. If more able people get more education and earn more (for reasons unrelated to school), the OLS coefficient captures both effects.
But is ability bias necessarily upward? The answer is not obvious:
- Arguments for upward bias (the standard view): Higher IQ → stay in school longer AND earn more. Schools select on test scores. More-educated parents invest more in their children’s education. All of these create positive correlation between ability and schooling.
- Arguments for downward bias (the contrarian view): Some highly talented people leave school early to pursue lucrative opportunities. Bill Gates, Mark Zuckerberg, and Steve Jobs dropped out of college; Mick Jagger left the London School of Economics to form the Rolling Stones. If such exceptional ability is negatively correlated with schooling, OLS could actually understate the true return.
- For most people, the standard view probably holds: the college-dropout billionaires are rare exceptions. But the ambiguity is important because it means we cannot assume the direction of OLS bias without evidence.
To understand how much of this 7% estimate is causal, we need to think carefully about omitted variables.
Multiple Regression and the OVB Problem
Adding Controls
Chapter 2 taught us that adding control variables can reduce omitted variables bias — as long as the controls are not “bad controls” (caused by the treatment). The long regression adds observable controls to the bivariate equation:
\[\ln W_i = \alpha + \rho \, S_i + \gamma_1 \, \text{Age}_i + \gamma_2 \, \text{Age}_i^2 + \gamma_3 \, \text{Female}_i + \gamma_4 \, \text{White}_i + e_i\]
where \(S_i\) is years of education (educ), and the \(\gamma\) coefficients capture the effects of age (age, age2), gender (female), and race (white). If ability remains in \(e_i\), then \(\hat{\rho}\) is still biased — adding observable controls only helps if they capture the omitted confounders. Let’s see this using the Twinsburg twins data.
Code
# Load clean twins data (340 twin pairs from Twinsburg, Ohio)
twins = pd.read_csv(GITHUB_DATA_URL + "ch6/twins_clean.csv")
# Key variables:
# lwage = log weekly wage; educ = own years of education
# educt_t = twin's report of respondent's education (instrument)
# first = 1 for the first twin in each pair (use to avoid double-counting)
# dlwage = within-pair difference in log wages; deduc = difference in own-reported education
# deduct = difference in twin's report of education (instrument for deduc)
twins.head(3)| lwage | educ | educt_t | age | age2 | female | white | first | dlwage | deduc | deduct | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2.479523 | 16.0 | 16.0 | 33.251190 | 11.056416 | 1.0 | 1.0 | 1.0 | 0.259346 | 0.0 | 0.0 |
| 1 | 2.220177 | 16.0 | 16.0 | 33.251190 | 11.056416 | 1.0 | 1.0 | NaN | -0.259346 | 0.0 | 0.0 |
| 2 | 2.228209 | 12.0 | 12.0 | 43.570145 | 18.983576 | 1.0 | 1.0 | NaN | -0.721318 | -6.0 | -4.0 |
Code
# OLS: regress log wages on education with demographic controls
ols = pf.feols("lwage ~ educ + age + age2 + female + white", data=twins, vcov="hetero")
# Extract key regression results into a clear table
pd.DataFrame({
"Variable": ols.coef().index,
"Coefficient": ols.coef().round(4).values,
"Std. Error": ols.se().round(4).values,
"t-statistic": ols.tstat().round(2).values,
"p-value": ols.pvalue().round(3).values,
})| Variable | Coefficient | Std. Error | t-statistic | p-value | |
|---|---|---|---|---|---|
| 0 | Intercept | -1.0949 | 0.2924 | -3.74 | 0.000 |
| 1 | educ | 0.1100 | 0.0105 | 10.50 | 0.000 |
| 2 | age | 0.1039 | 0.0120 | 8.67 | 0.000 |
| 3 | age2 | -0.1063 | 0.0147 | -7.23 | 0.000 |
| 4 | female | -0.3180 | 0.0399 | -7.97 | 0.000 |
| 5 | white | -0.1001 | 0.0682 | -1.47 | 0.143 |
The OLS return with controls is about 11% per year of schooling. Note that this estimate uses a different dataset (the Twinsburg twins) than the bivariate regression above (the 1980 Census). The higher estimate partly reflects the different sample. Even within this dataset, adding demographic controls does not substantially reduce the schooling coefficient — because these observables explain little of the ability-education correlation.
The OVB Formula Applied to Schooling
From Chapter 2, the omitted variables bias formula is:
\[\text{OVB} = \underbrace{\gamma}_{\text{effect of ability on earnings}} \times \underbrace{\pi_1}_{\text{correlation of ability with schooling}}\]
For schooling:
- \(\gamma > 0\): More able people earn more, holding schooling constant
- \(\pi_1 > 0\): More able people get more education
Therefore \(\text{OVB} > 0\), and OLS overstates the true return. The short regression (without ability) gives a coefficient that is too large.
Seeing OVB in Action
To see this concretely, we use a synthetic dataset where we know the true causal return (about 0.09 per year) because we designed the data-generating process.
NoteSynthetic data
This dataset was designed to illustrate the OVB concept. It contains 2,000 simulated individuals with schooling, earnings, unobserved ability, and occupation. The true total causal return to schooling is about 0.09 (9%) per year — combining a direct effect on earnings and an indirect effect through occupation.
Code
# Load synthetic OVB data (2000 simulated individuals)
ovb = pd.read_csv(GITHUB_DATA_URL + "ch6/synthetic_ovb.csv")
# Short regression: omit ability (like real life — we can't observe ability)
short_reg = pf.feols("earnings ~ schooling", data=ovb, vcov="hetero")
# Long regression: include ability (the "oracle" regression we can't run with real data)
long_reg = pf.feols("earnings ~ schooling + ability", data=ovb, vcov="hetero")
# Compare coefficients
pd.DataFrame({
"Specification": ["Short (omit ability)", "Long (include ability)", "True causal return"],
"Schooling coefficient": [
f"{short_reg.coef()['schooling']:.4f} ({short_reg.se()['schooling']:.4f})",
f"{long_reg.coef()['schooling']:.4f} ({long_reg.se()['schooling']:.4f})",
"0.0900",
],
})| Specification | Schooling coefficient | |
|---|---|---|
| 0 | Short (omit ability) | 0.1229 (0.0024) |
| 1 | Long (include ability) | 0.0853 (0.0036) |
| 2 | True causal return | 0.0900 |
The short regression gives about 0.12 — overstating the true return by roughly 40%. Adding the unobservable ability recovers the true total causal return (about 0.09). In real life, we cannot observe ability, so we need a different strategy.
Bad Controls: Do Not Control for Occupation
WarningBad controls
Occupation is caused by education — it is a “bad control” (a mediator or post-treatment variable). Controlling for it absorbs part of the causal effect of education on earnings, biasing the estimate downward. If education raises earnings partly by giving access to higher-paying occupations, then holding occupation constant removes that channel.
Code
# Bad control: add occupation (which is caused by schooling)
bad_control = pf.feols("earnings ~ schooling + occupation", data=ovb, vcov="hetero")
pd.DataFrame({
"Specification": ["Without occupation", "With occupation (bad control)", "True causal return"],
"Schooling coefficient": [
f"{short_reg.coef()['schooling']:.4f} ({short_reg.se()['schooling']:.4f})",
f"{bad_control.coef()['schooling']:.4f} ({bad_control.se()['schooling']:.4f})",
"0.0900",
],
})| Specification | Schooling coefficient | |
|---|---|---|
| 0 | Without occupation | 0.1229 (0.0024) |
| 1 | With occupation (bad control) | 0.1002 (0.0032) |
| 2 | True causal return | 0.0900 |
Adding occupation shrinks the schooling coefficient — not because it reduces bias, but because it removes a real causal channel. Rule of thumb: never control for variables that are consequences of the treatment.
Even with good controls, we can never be sure we have accounted for all confounders. What we really want is a research design — like the randomized experiments in Chapter 1 — that eliminates ability bias by construction.
Why Not an RCT?
The gold standard for causal inference is the randomized controlled trial: randomly assign some people to get more education, and compare their earnings to a control group. Random assignment breaks the link between ability and education, so the simple difference in means is causal.
But we cannot randomize education. It would be unethical and impractical to force some people to drop out and others to stay in school for 20 years.
To see why random assignment works, consider the regression of earnings on the randomly assigned scholarship:
\[\ln W_i = \alpha + \beta \, P_i + e_i\]
where \(P_i\) = 1 if individual \(i\) received a scholarship (scholarship). Because \(P_i\) is randomly assigned, it is uncorrelated with ability in \(e_i\), so \(\hat{\beta}\) is unbiased. The per-year causal return is then:
\[\hat{\rho} = \frac{\hat{\beta}}{\text{Schooling difference}} = \frac{\text{Reduced form}}{\text{First stage}}\]
This is the Wald estimator from Chapter 3, applied to the scholarship “instrument.” We use a synthetic dataset to demonstrate this.
NoteSynthetic data
This dataset simulates a hypothetical scholarship experiment. 2,000 individuals were randomly assigned to receive a scholarship (or not). The scholarship increases schooling by about 2 years. The true causal return to schooling is 0.08 per year, so the scholarship should increase earnings by about 0.16.
Code
# Load synthetic RCT data
rct = pd.read_csv(GITHUB_DATA_URL + "ch6/synthetic_rct.csv")
# Simple comparison of means by scholarship status
means = rct.groupby("scholarship")[["schooling", "earnings"]].mean()
diff_school = means.loc[1, "schooling"] - means.loc[0, "schooling"]
diff_earn = means.loc[1, "earnings"] - means.loc[0, "earnings"]
# Regression of earnings on scholarship (= difference in means)
rct_reg = pf.feols("earnings ~ scholarship", data=rct, vcov="hetero")
# Wald estimate: earnings effect / schooling effect = per-year return
wald_rct = diff_earn / diff_school
pd.DataFrame({
"Quantity": [
"Scholarship → schooling (first stage)",
"Scholarship → earnings (reduced form)",
"Per-year return (reduced form / first stage)",
],
"Estimate": [
f"{diff_school:.3f} years",
f"{diff_earn:.4f} log points",
f"{wald_rct:.4f}",
],
})| Quantity | Estimate | |
|---|---|---|
| 0 | Scholarship → schooling (first stage) | 1.958 years |
| 1 | Scholarship → earnings (reduced form) | 0.1605 log points |
| 2 | Per-year return (reduced form / first stage) | 0.0820 |
With random assignment, the simple difference in earnings between scholarship and non-scholarship groups gives an unbiased estimate of the causal effect. Dividing by the schooling difference gives the per-year return — close to the true 0.08.
ImportantThe lesson
The RCT recovers the right answer because random assignment makes the scholarship independent of ability. Since the scholarship affects earnings only through schooling, the Wald ratio (earnings effect / schooling effect) gives an unbiased per-year return. But since we cannot run a real schooling RCT, we need quasi-experimental methods that approximate random assignment. The rest of this chapter explores four such strategies.
Strategy 1: Twin Comparisons
The Logic
Identical twins share genes and family upbringing — the very factors we suspect drive ability bias. If one twin gets more education than the other, the earnings difference within the pair reflects the causal return, not ability.
Within-Twin Differences
By taking the difference within each twin pair, we eliminate everything shared between them:
\[\Delta Y_f = \rho \cdot \Delta S_f + \Delta e_f\]
where \(\Delta Y_f\) is the difference in log wages (dlwage) and \(\Delta S_f\) is the difference in years of education (deduc) within twin pair \(f\). Shared ability cancels out because both twins have the same value.
Code
# Use only the first twin in each pair (to avoid double-counting)
first = twins[twins["first"] == 1]
# Regress wage difference on education difference
# The "- 1" removes the intercept: when both twins have the same education,
# we expect zero wage difference, so there's no constant term needed
twin_fe = pf.feols("dlwage ~ deduc - 1", data=first, vcov="hetero")
# Extract key regression results into a clear table
pd.DataFrame({
"Variable": twin_fe.coef().index,
"Coefficient": twin_fe.coef().round(4).values,
"Std. Error": twin_fe.se().round(4).values,
"t-statistic": twin_fe.tstat().round(2).values,
"p-value": twin_fe.pvalue().round(3).values,
})| Variable | Coefficient | Std. Error | t-statistic | p-value | |
|---|---|---|---|---|---|
| 0 | deduc | 0.0617 | 0.0198 | 3.12 | 0.002 |
The twin estimate drops to about 6% — nearly half the OLS estimate. This suggests ability bias pushes OLS upward.
WarningCommon Misconception: A lower estimate is not necessarily a better estimate
Twin FE gives 0.06. OLS gives 0.11. Students often assume the lower number must be “more correct.”
This is wrong. Twin FE has its own bias: measurement error amplification.
Here’s why: twins report their own education. Small errors (misremembering a year) get amplified by differencing. The true within-pair variation in schooling is tiny. So even small errors dominate the signal.
Result: This attenuation bias pushes the twin estimate below the true return.
Formally, measurement error biases the twin FE coefficient by the reliability ratio:
\[\hat{\rho}_{FE} \approx \rho \times \underbrace{\frac{\text{Var}(\Delta S^*_f)}{\text{Var}(\Delta S^*_f) + \text{Var}(\Delta m_f)}}_{\text{reliability ratio}}\]
where \(\Delta S^*_f\) is the true within-twin difference in schooling and \(\Delta m_f\) is the measurement error in the differenced data. When twins are very similar, \(\text{Var}(\Delta S^*)\) is small but \(\text{Var}(\Delta m)\) stays the same size, so the reliability ratio drops well below 1 and \(\hat{\rho}_{FE}\) is attenuated toward zero. A reliability ratio of 0.5 would cut the estimate in half.
IV: Using the Twin’s Report as an Instrument
The twin estimate may be biased downward by measurement error in self-reported education. If twins misremember their schooling, the differenced data amplifies noise relative to signal.
The fix: use each twin’s report of the other’s education as an instrument. This report is correlated with true education but has independent measurement error, so it satisfies the IV requirements. (This assumes twins do not simply agree on inaccurate reports. If twins discuss their education and reach consensus, their measurement errors may be correlated, weakening the IV correction.)
NoteReading the pyfixest IV formula syntax
In pyfixest, the IV formula uses a pipe (|) to specify the endogenous variable and its instrument:
| educ ~ educt_tmeans: educ is the endogenous variable, instrumented by educt_t- Controls go before the first
|; fixed effects (if any) go between the first and second| vcov="hetero"gives heteroskedasticity-robust standard errors (HC1)
The twin IV corrects measurement error using two stages. In the within-pair (differenced) version:
First stage: Predict own-reported schooling difference using the twin’s report
\[\Delta S_f = \pi_0 + \pi_1 \, \Delta S^{twin}_f + v_f\]
Second stage: Regress wage difference on the predicted schooling difference
\[\Delta Y_f = \rho_{IV} \, \widehat{\Delta S}_f + u_f\]
where \(\Delta S^{twin}_f\) is the difference in the twin’s report of the other’s education (deduct), and \(\widehat{\Delta S}_f\) is the fitted value from the first stage. Because the twin’s report has independent measurement error, it filters out the noise in own-reported education, correcting the attenuation bias.
Code
# IV in levels: instrument own education (educ) with twin's report (educt_t)
iv_levels = pf.feols("lwage ~ 1 + age + age2 + female + white | educ ~ educt_t", data=twins, vcov="hetero")
# IV in differences: instrument own-reported difference (deduc) with twin's report diff (deduct)
first_iv = first[["dlwage", "deduc", "deduct"]].dropna()
iv_diff = pf.feols("dlwage ~ 0 | deduc ~ deduct", data=first_iv, vcov="hetero")
# Combine all four estimates into one table
ols_coef = round(ols.coef()["educ"], 3)
ols_se = round(ols.se()["educ"], 3)
fe_coef = round(twin_fe.coef()["deduc"], 3)
fe_se = round(twin_fe.se()["deduc"], 3)
iv_lev_coef = round(iv_levels.coef()["educ"], 3)
iv_lev_se = round(iv_levels.se()["educ"], 3)
iv_dif_coef = round(iv_diff.coef()["deduc"], 3)
iv_dif_se = round(iv_diff.se()["deduc"], 3)
pd.DataFrame({
"Method": ["OLS (levels)", "Twin FE (differences)", "IV (levels)", "IV (differences)"],
"Return to schooling": [
format(ols_coef, ".3f") + " (" + format(ols_se, ".3f") + ")",
format(fe_coef, ".3f") + " (" + format(fe_se, ".3f") + ")",
format(iv_lev_coef, ".3f") + " (" + format(iv_lev_se, ".3f") + ")",
format(iv_dif_coef, ".3f") + " (" + format(iv_dif_se, ".3f") + ")",
],
})| Method | Return to schooling | |
|---|---|---|
| 0 | OLS (levels) | 0.110 (0.010) |
| 1 | Twin FE (differences) | 0.062 (0.020) |
| 2 | IV (levels) | 0.116 (0.011) |
| 3 | IV (differences) | 0.108 (0.034) |
ImportantWhat the twin results tell us
| Method | Estimate | Interpretation |
|---|---|---|
| OLS | ~0.11 | Likely biased UP by ability |
| Twin FE | ~0.06 | Biased DOWN by measurement error |
| IV (levels) | ~0.12 | Corrects measurement error in levels |
| IV (differences) | ~0.11 | Corrects measurement error in differences |
The true return is probably 8–11% per year, with OLS slightly overstating and twin FE understating due to different biases.
NoteIntuition Builder: The Bathroom Scale Analogy
Imagine weighing yourself on a bathroom scale that randomly adds or subtracts 5 pounds. On average, the scale is right — but any single reading is noisy. Now suppose you weigh yourself in the morning and evening to measure how much weight you gained during the day. The true gain might be 0.5 lbs, but the scale’s error (±5 lbs in each reading) means the difference between readings is dominated by noise. This is exactly what happens with twin differences in education: the true within-pair variation is small (twins are similar), but measurement error stays the same size, so noise overwhelms the signal.
Lessons from the twins strategy:
- Twin FE controls for shared ability but amplifies measurement error — two biases push in opposite directions
- IV using the twin’s report corrects measurement error, recovering a return near 11%
- Limitation: The Twinsburg twins are a self-selected sample (twins who attend an annual twin festival in Ohio). They may not represent the general population
The twins approach offered a first crack at ability bias but raised a new concern: measurement error. Our next strategy sidesteps both problems by finding a source of schooling variation that is entirely independent of ability — and precisely measured in census data.
Strategy 2: Quarter-of-Birth IV
Research question: What is the causal return to an additional year of schooling, using a source of variation that is independent of ability?
The data: Angrist and Krueger (1991) used the 1980 U.S. Census, extracting 329,509 men born between 1930 and 1939. The outcome is log weekly earnings (lnw). Schooling is measured in years (s). Quarter of birth (qob, 1–4) serves as the instrument.
The Idea
Compulsory schooling laws allow students to drop out at age 16. Because school-entry rules are based on birth date cutoffs, children born later in the year start school younger and accumulate more schooling before reaching the dropout age.
This creates an instrument: quarter of birth affects schooling (through compulsory attendance rules) but should not directly affect earnings.
The IV strategy has three equations:
First stage (instrument predicts schooling):
\[S_i = \alpha_1 + \phi \, Q4_i + e_{1i}\]
Reduced form (instrument predicts earnings directly):
\[\ln W_i = \alpha_2 + \rho_{RF} \, Q4_i + e_{2i}\]
Wald estimator (ratio gives the causal return):
\[\hat{\rho}_{IV} = \frac{\hat{\rho}_{RF}}{\hat{\phi}} = \frac{\text{Effect of } Q4 \text{ on earnings}}{\text{Effect of } Q4 \text{ on schooling}}\]
where \(Q4_i\) = 1 if individual \(i\) was born in the fourth quarter (q4), \(S_i\) is years of schooling (s), and \(\ln W_i\) is log weekly earnings (lnw). This estimate is a LATE (Local Average Treatment Effect): it applies only to compliers whose schooling was changed by compulsory attendance interacting with their birth quarter.
The IV Recipe: Step by Step
Code
# Step 1: Reduced form — does Q4 birth predict higher earnings?
rf = pf.feols("lnw ~ q4", data=qob, vcov="hetero")
# Step 2: First stage — does Q4 birth predict more schooling?
fs = pf.feols("s ~ q4", data=qob, vcov="hetero")
# Step 3: Wald estimate = reduced form / first stage
wald = rf.coef()["q4"] / fs.coef()["q4"]
# Step 4: Verify with 2SLS
iv = pf.feols("lnw ~ 1 | s ~ q4", data=qob, vcov="hetero")
# Extract coefficients and standard errors
rf_coef = round(rf.coef()["q4"], 4)
rf_se = round(rf.se()["q4"], 4)
fs_coef = round(fs.coef()["q4"], 4)
fs_se = round(fs.se()["q4"], 4)
wald_rounded = round(wald, 4)
iv_coef = round(iv.coef()["s"], 4)
iv_se = round(iv.se()["s"], 4)
pd.DataFrame({
"Step": ["Reduced form (Q4 → earnings)", "First stage (Q4 → schooling)",
"Wald estimate (RF / FS)", "2SLS verification"],
"Estimate": [
format(rf_coef, ".4f") + " (" + format(rf_se, ".4f") + ")",
format(fs_coef, ".4f") + " (" + format(fs_se, ".4f") + ")",
format(wald_rounded, ".4f"),
format(iv_coef, ".4f") + " (" + format(iv_se, ".4f") + ")",
],
})| Step | Estimate | |
|---|---|---|
| 0 | Reduced form (Q4 → earnings) | 0.0068 (0.0027) |
| 1 | First stage (Q4 → schooling) | 0.0921 (0.0132) |
| 2 | Wald estimate (RF / FS) | 0.0740 |
| 3 | 2SLS verification | 0.0740 (0.0280) |
The reduced form shows that Q4 births earn slightly more. The first stage shows they get about 0.09 more years of schooling. Dividing gives the Wald estimate of about 7% per year — which the 2SLS verification confirms.
Visualizing the First Stage and Reduced Form
Code
# Collapse to cell means by age (= birth cohort)
cell = qob.groupby("age").agg(s=("s","mean"), lnw=("lnw","mean"),
q4=("q4","mean"), q1=("q1","mean")).reset_index()
cell["yob"] = 80 - cell["age"]
cell["is_q4"] = cell["q4"] > 0.5
cell["is_q1"] = cell["q1"] > 0.5
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
ax = axes[0]
ax.plot(cell["yob"], cell["s"], "k-", alpha=0.4)
ax.scatter(cell.loc[cell["is_q4"], "yob"], cell.loc[cell["is_q4"], "s"],
color="black", s=50, zorder=5, label="Quarter 4")
ax.scatter(cell.loc[cell["is_q1"], "yob"], cell.loc[cell["is_q1"], "s"],
facecolors="none", edgecolors="black", s=50, zorder=5, label="Quarter 1")
ax.set_xlabel("Year of Birth")
ax.set_ylabel("Years of Education")
ax.set_title("First Stage")
ax.legend()
ax = axes[1]
ax.plot(cell["yob"], cell["lnw"], "k-", alpha=0.4)
ax.scatter(cell.loc[cell["is_q4"], "yob"], cell.loc[cell["is_q4"], "lnw"],
color="black", s=50, zorder=5, label="Quarter 4")
ax.scatter(cell.loc[cell["is_q1"], "yob"], cell.loc[cell["is_q1"], "lnw"],
facecolors="none", edgecolors="black", s=50, zorder=5, label="Quarter 1")
ax.set_xlabel("Year of Birth")
ax.set_ylabel("Log Weekly Earnings")
ax.set_title("Reduced Form")
ax.legend()
plt.tight_layout()
plt.show()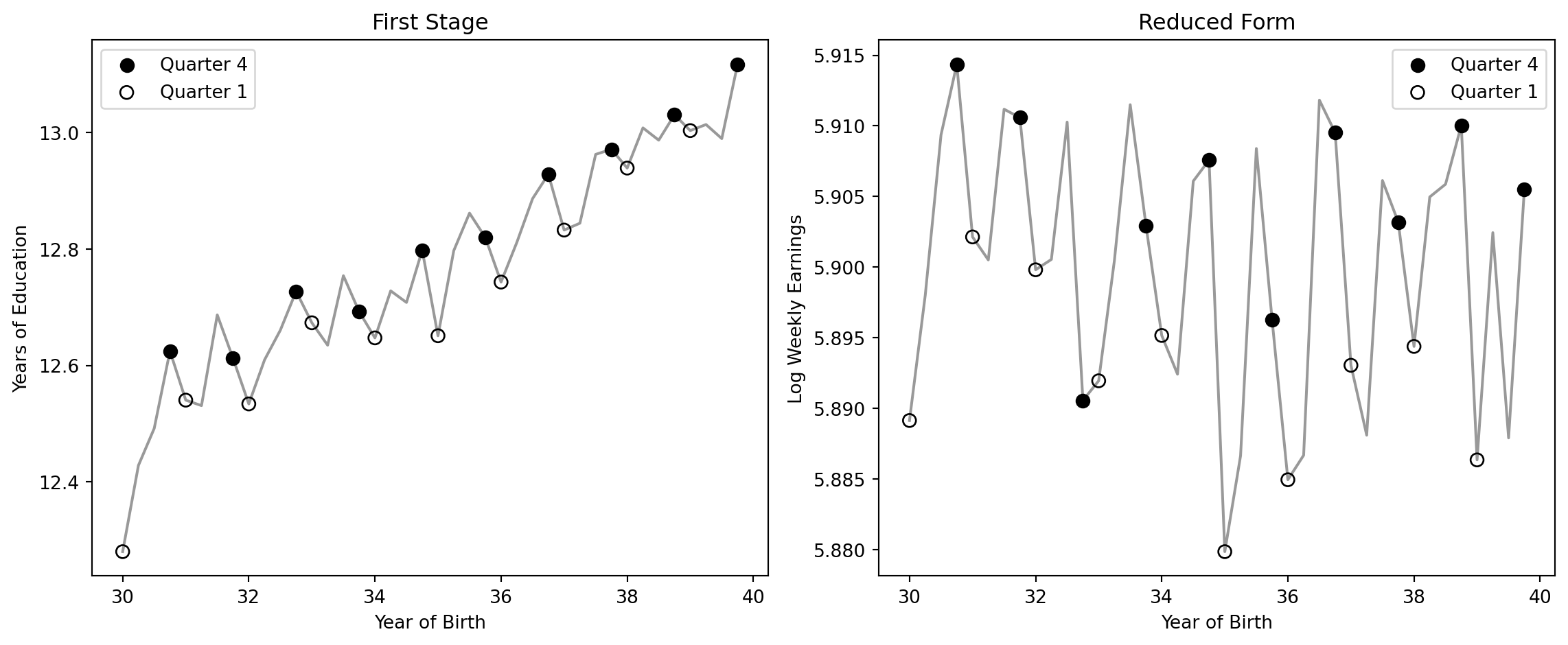
NoteWho are the compliers?
The QOB IV estimate is a LATE (Local Average Treatment Effect) — it applies only to compliers, people whose schooling was actually changed by their quarter of birth interacting with compulsory schooling laws. Compliers are students at the dropout threshold. Students who would have attended college regardless (always-takers) or those who drop out very early (never-takers) are not affected by the instrument.
The quarter-of-birth IV uses a clever natural experiment, but it relies on a single source of variation. Our next strategy uses a different set of instruments — compulsory schooling laws that vary across states.
Strategy 3: Child Labor Law IV
Research question: Do compulsory schooling laws that forced children to enter school by certain ages provide another valid instrument for estimating the return to education?
The data: Acemoglu and Angrist used data on compulsory schooling laws that varied across U.S. states. Three instruments capture whether a state required children to enter school by age 7 (cl7), 8 (cl8), or 9 (cl9). The data has been collapsed to state-of-birth × year-of-birth × census-year cell means.
With multiple instruments and fixed effects, the 2SLS framework is:
First stage: Predict schooling using the three compulsory schooling instruments
\[S_{scy} = \alpha_1 + \phi_1 \, CL7_{sc} + \phi_2 \, CL8_{sc} + \phi_3 \, CL9_{sc} + \beta_s + \gamma_c + \delta_y + v_{scy}\]
Second stage: Regress earnings on the predicted schooling
\[\ln W_{scy} = \alpha_2 + \rho_{IV} \, \hat{S}_{scy} + \beta_s + \gamma_c + \delta_y + u_{scy}\]
where:
- \(CL7\), \(CL8\), \(CL9\) = indicators for compulsory school entry by age 7, 8, or 9 (
cl7,cl8,cl9) - \(\beta_s\) = state-of-birth fixed effects (
| sob) - \(\gamma_c\) = year-of-birth cohort effects (
| yob) - \(\delta_y\) = census-year effects (
| year) - \(\hat{S}_{scy}\) = the fitted value of schooling from the first stage
- \(\rho_{IV}\) = the causal return to schooling, identified by the three instruments jointly
Code
# Load child labor law data (collapsed cell means, ~2400 observations)
cl = pd.read_csv(GITHUB_DATA_URL + "ch6/childlabor_clean.csv")
cl.head(3)| sob | yob | year | lnwkwage | indEduc | cl7 | cl8 | cl9 | weight | n | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1900 | 1950 | 3.772292 | 7.428592 | 0 | 0 | 0 | 6862.0 | 21 |
| 1 | 1 | 1901 | 1950 | 3.752198 | 8.464196 | 0 | 0 | 0 | 9147.0 | 28 |
| 2 | 1 | 1902 | 1950 | 4.129656 | 7.740741 | 0 | 0 | 0 | 8829.0 | 27 |
Code
# First stage: do child labor laws predict education?
fs_cl = pf.feols("indEduc ~ cl7 + cl8 + cl9 | sob + yob + year",
data=cl, weights="weight", vcov={"CRV1": "sob"})
# Joint F-test on instruments (Wald test)
import numpy as np
coefs = np.array([fs_cl.coef()['cl7'], fs_cl.coef()['cl8'], fs_cl.coef()['cl9']])
idx = [list(fs_cl.coef().index).index(v) for v in ['cl7', 'cl8', 'cl9']]
V_sub = fs_cl._vcov[np.ix_(idx, idx)]
f_stat = float(coefs @ np.linalg.inv(V_sub) @ coefs / 3)
pd.DataFrame({
"Instrument": ["cl7 (enter by age 7)", "cl8 (enter by age 8)", "cl9 (enter by age 9)", "Joint F-statistic"],
"Coefficient": [
f"{fs_cl.coef()['cl7']:.4f} ({fs_cl.se()['cl7']:.4f})",
f"{fs_cl.coef()['cl8']:.4f} ({fs_cl.se()['cl8']:.4f})",
f"{fs_cl.coef()['cl9']:.4f} ({fs_cl.se()['cl9']:.4f})",
f"{f_stat:.2f}",
],
})| Instrument | Coefficient | |
|---|---|---|
| 0 | cl7 (enter by age 7) | 0.1690 (0.0674) |
| 1 | cl8 (enter by age 8) | 0.1872 (0.0621) |
| 2 | cl9 (enter by age 9) | 0.3973 (0.0984) |
| 3 | Joint F-statistic | 6.06 |
Code
# OLS with fixed effects
ols_cl = pf.feols("lnwkwage ~ indEduc | sob + yob + year",
data=cl, weights="weight", vcov={"CRV1": "sob"})
# IV/2SLS with fixed effects and multiple instruments
iv_result = pf.feols("lnwkwage ~ 1 | sob + yob + year | indEduc ~ cl7 + cl8 + cl9",
data=cl, weights="weight", vcov={"CRV1": "sob"})
pd.DataFrame({
"Method": ["OLS (with state, YOB, year FE)", "IV/2SLS (child labor law instruments)"],
"Return to schooling": [
f"{ols_cl.coef()['indEduc']:.4f} ({ols_cl.se()['indEduc']:.4f})",
f"{iv_result.coef()['indEduc']:.4f} ({iv_result.se()['indEduc']:.4f})",
],
})| Method | Return to schooling | |
|---|---|---|
| 0 | OLS (with state, YOB, year FE) | 0.0698 (0.0066) |
| 1 | IV/2SLS (child labor law instruments) | 0.1288 (0.0371) |
ImportantWhat the child labor law results tell us
The OLS estimate with fixed effects gives about 7%, while the IV estimate is larger at about 13%. The IV estimate is less precise than the QOB results, in part because the first-stage F-statistic is below 10 — a sign of weak instruments that can inflate IV estimates. Despite the imprecision, the results are broadly consistent with the other IV strategies in pointing to a causal return that is at least as large as the OLS estimate.
Both the twins and IV strategies estimate the overall return to education. But they leave open a deeper question: does education raise earnings because of the skills you learn, or because employers value the diploma?
Strategy 4: Sheepskin Effects via RD
Research question: Does the diploma credential itself boost earnings (the signaling view), or is it the skills learned in school that matter (the human capital view)?
The data: Clark and Martorell (2014) studied the Texas high school exit exam. The data consists of 46 score bins around the passing cutoff. The running variable is the test score relative to the passing threshold (minscore, where 0 = cutoff).
Why RD works here: Students who scored just above vs. just below the cutoff have nearly identical skills but very different diploma rates. Any jump in earnings at the cutoff reflects the value of the diploma credential itself.
The RD regression estimates the jump at the passing threshold:
\[Y_i = \alpha + \rho \, D_i + f(\text{Score}_i) + e_i\]
where:
- \(Y_i\) = average annual earnings (
avgearnings) or diploma receipt (receivehsd) - \(D_i\) = 1 if the student passed the last-chance exam (
pass_exam) - \(f(\text{Score}_i)\) = a flexible polynomial in the test score relative to the cutoff (
minscore), fitted separately on each side of the threshold - \(\rho\) = the sheepskin effect — the jump in the outcome at the passing threshold
If \(\rho\) is large for earnings, the diploma itself has value (signaling). If \(\rho \approx 0\), the diploma credential adds little beyond the skills already reflected in the score.
Code
# Load clean sheepskin RD data (Texas last-chance exam)
sheep = pd.read_csv(GITHUB_DATA_URL + "ch6/sheepskin_clean.csv")
sheep.head(3)| minscore | pass_exam | receivehsd | avgearnings | n | person_years | left_1 | right_1 | left_2 | right_2 | left_3 | right_3 | left_4 | right_4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -30.0 | 0 | 0.416667 | 11845.086 | 12 | 24.0 | -30.0 | -0.0 | 900.0 | 0.0 | -27000.0 | -0.0 | 810000.0 | 0.0 |
| 1 | -29.0 | 0 | 0.387097 | 9205.679 | 31 | 104.0 | -29.0 | -0.0 | 841.0 | 0.0 | -24389.0 | -0.0 | 707281.0 | 0.0 |
| 2 | -28.0 | 0 | 0.318182 | 8407.745 | 44 | 146.0 | -28.0 | -0.0 | 784.0 | 0.0 | -21952.0 | -0.0 | 614656.0 | 0.0 |
Code
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
# --- Panel 1: Diploma receipt ---
ax = axes[0]
ax.scatter(sheep["minscore"], sheep["receivehsd"], color="black", s=20, alpha=0.6)
left = sheep[sheep["minscore"] < 0]
right = sheep[sheep["minscore"] >= 0]
fit_l = pf.feols("receivehsd ~ pass_exam + left_1 + left_2 + left_3 + left_4", data=left, weights="n")
fit_r = pf.feols("receivehsd ~ pass_exam + right_1 + right_2 + right_3 + right_4", data=right, weights="n")
left_plot = sheep[sheep["minscore"] <= 0].copy()
left_plot["fit"] = fit_l.predict(newdata=left_plot)
right_plot = sheep[sheep["minscore"] >= 0].copy()
right_plot["fit"] = fit_r.predict(newdata=right_plot)
ax.plot(left_plot["minscore"], left_plot["fit"], "k-", linewidth=2)
ax.plot(right_plot["minscore"], right_plot["fit"], "k-", linewidth=2)
ax.axvline(x=0, color="red", linestyle="--", alpha=0.5)
ax.set_xlabel("Test score relative to cutoff")
ax.set_ylabel("Fraction receiving diploma")
ax.set_title("Diploma Receipt (First Stage)")
ax.set_xlim(-30, 15)
ax.set_ylim(0, 1)
# --- Panel 2: Earnings ---
ax = axes[1]
ax.scatter(sheep["minscore"], sheep["avgearnings"], color="black", s=20, alpha=0.6)
earn_l = pf.feols("avgearnings ~ pass_exam + left_1 + left_2 + left_3 + left_4",
data=left[left["minscore"] >= -30], weights="person_years")
earn_r = pf.feols("avgearnings ~ pass_exam + right_1 + right_2 + right_3 + right_4", data=right, weights="person_years")
left_earn = sheep[sheep["minscore"] <= 0].copy()
left_earn["fit"] = earn_l.predict(newdata=left_earn)
right_earn = sheep[sheep["minscore"] >= 0].copy()
right_earn["fit"] = earn_r.predict(newdata=right_earn)
ax.plot(left_earn["minscore"], left_earn["fit"], "k-", linewidth=2)
ax.plot(right_earn["minscore"], right_earn["fit"], "k-", linewidth=2)
ax.axvline(x=0, color="red", linestyle="--", alpha=0.5)
ax.set_xlabel("Test score relative to cutoff")
ax.set_ylabel("Annual Earnings ($)")
ax.set_title("Earnings (Reduced Form)")
ax.set_xlim(-30, 15)
plt.tight_layout()
plt.show()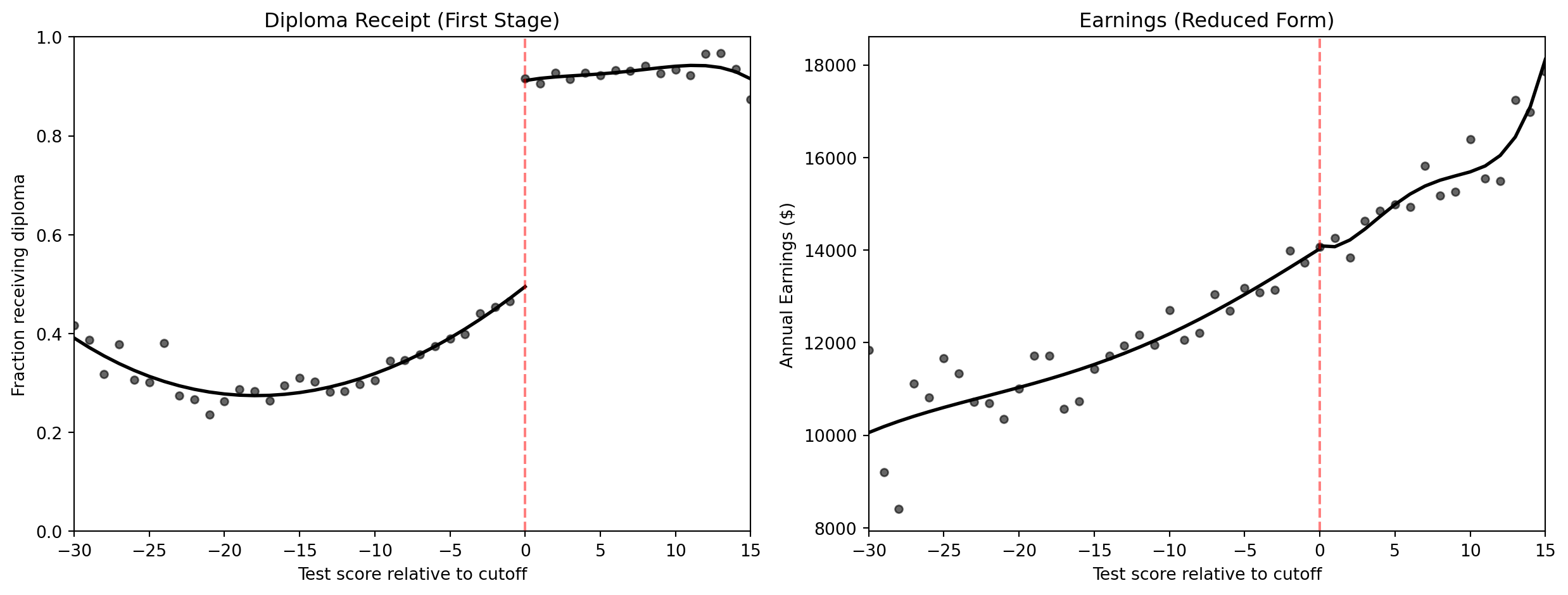
ImportantThe sheepskin verdict
- Diploma receipt jumps by about 40 percentage points at the cutoff (a strong first stage). Since the jump is 40 points rather than 100, this is technically a fuzzy RD — passing the exam increases but does not guarantee diploma receipt
- Earnings show almost no jump — the RD effect is near zero. Even scaling by the diploma receipt jump (the fuzzy RD Wald estimate), the credential effect remains negligible
- Most of the education premium reflects actual learning (human capital), not just the piece of paper (signaling)
We have now applied regression, IV, and RD to the schooling question. The final method — differences-in-differences — exploits policy changes over time.
Strategy 5: Differences-in-Differences
Research question: Can we estimate the return to schooling by comparing states that changed their compulsory schooling laws to states that did not?
NoteSynthetic data
This dataset simulates a compulsory schooling reform adopted by 10 out of 20 states in 2005. It was designed to illustrate the DiD concept with clear parallel pre-trends and a visible treatment effect.
The DD estimator compares changes over time across treated and control groups:
\[\delta_{DD} = \underbrace{(\bar{Y}_{treat,after} - \bar{Y}_{treat,before})}_{\text{Change in treated states}} - \underbrace{(\bar{Y}_{control,after} - \bar{Y}_{control,before})}_{\text{Change in control states}}\]
In regression form with state and year fixed effects:
\[Y_{st} = \alpha + \delta \, (\text{Treated}_s \times \text{Post}_t) + \beta_s + \gamma_t + e_{st}\]
where:
- \(Y_{st}\) = average earnings (
avg_earnings) or average schooling (avg_schooling) in state \(s\) at time \(t\) - \(\text{Treated}_s \times \text{Post}_t\) = the interaction term (
treat_post), equal to 1 for treated states after the reform - \(\beta_s\) = state fixed effects (
| state) — absorb permanent differences between states - \(\gamma_t\) = year fixed effects (
| year) — absorb common time trends - \(\delta\) = the DD estimate of the reform’s causal effect
The parallel trends assumption requires that treated and control states would have followed the same trajectory absent the reform: \(E[Y_{st}(0) \mid \text{Treated}=1] - E[Y_{st}(0) \mid \text{Treated}=0]\) is constant over time.
Code
# Load synthetic DiD data (20 states × 20 years)
did = pd.read_csv(GITHUB_DATA_URL + "ch6/synthetic_did.csv")
did.head(3)| state | year | treated | post | avg_schooling | avg_earnings | |
|---|---|---|---|---|---|---|
| 0 | 1 | 1995 | 1 | 0 | 11.4749 | 9.4303 |
| 1 | 1 | 1996 | 1 | 0 | 11.4804 | 9.3323 |
| 2 | 1 | 1997 | 1 | 0 | 11.4371 | 9.3873 |
Code
# Compute group means by year
group_means = did.groupby(["year", "treated"]).agg(
schooling=("avg_schooling", "mean"),
earnings=("avg_earnings", "mean"),
).reset_index()
treated_g = group_means[group_means["treated"] == 1]
control_g = group_means[group_means["treated"] == 0]
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
ax = axes[0]
ax.plot(treated_g["year"], treated_g["schooling"], "k-", linewidth=2, label="Treated states")
ax.plot(control_g["year"], control_g["schooling"], "k--", linewidth=2, label="Control states")
ax.axvline(x=2005, color="red", linestyle="--", alpha=0.5, label="Reform year")
ax.set_xlabel("Year")
ax.set_ylabel("Average Years of Schooling")
ax.set_title("Schooling (First Stage)")
ax.legend(loc="upper left")
ax = axes[1]
ax.plot(treated_g["year"], treated_g["earnings"], "k-", linewidth=2, label="Treated states")
ax.plot(control_g["year"], control_g["earnings"], "k--", linewidth=2, label="Control states")
ax.axvline(x=2005, color="red", linestyle="--", alpha=0.5, label="Reform year")
ax.set_xlabel("Year")
ax.set_ylabel("Log Average Earnings")
ax.set_title("Earnings (Reduced Form)")
ax.legend(loc="upper left")
plt.tight_layout()
plt.show()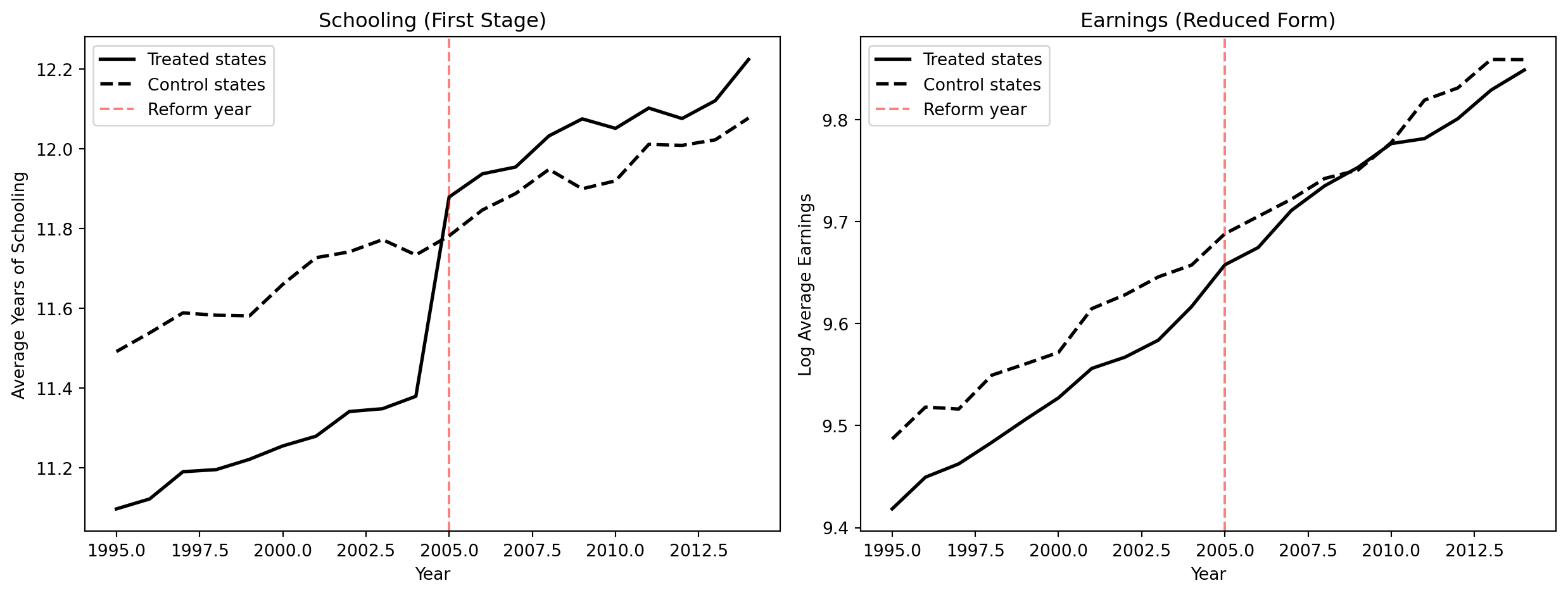
Code
# DD regression for schooling (first stage)
did["treat_post"] = did["treated"] * did["post"]
dd_school = pf.feols("avg_schooling ~ treat_post | state + year", data=did, vcov={"CRV1": "state"})
# DD regression for earnings (reduced form)
dd_earn = pf.feols("avg_earnings ~ treat_post | state + year", data=did, vcov={"CRV1": "state"})
# Implied return: earnings effect / schooling effect
dd_return = dd_earn.coef()["treat_post"] / dd_school.coef()["treat_post"]
pd.DataFrame({
"Quantity": [
"DD effect on schooling (first stage)",
"DD effect on earnings (reduced form)",
"Implied return per year (RF / FS)",
],
"Estimate": [
f"{dd_school.coef()['treat_post']:.4f} ({dd_school.se()['treat_post']:.4f})",
f"{dd_earn.coef()['treat_post']:.4f} ({dd_earn.se()['treat_post']:.4f})",
f"{dd_return:.4f}",
],
})| Quantity | Estimate | |
|---|---|---|
| 0 | DD effect on schooling (first stage) | 0.5039 (0.0165) |
| 1 | DD effect on earnings (reduced form) | 0.0393 (0.0055) |
| 2 | Implied return per year (RF / FS) | 0.0779 |
ImportantConnection to the child labor law IV
We borrow IV terminology here: the DD on schooling plays the role of a “first stage” (how much did the reform increase schooling?) and the DD on earnings plays the role of a “reduced form” (how much did the reform increase earnings?). The ratio gives the implied per-year return, just as the Wald estimator does in IV. This is valid as long as the reform affects earnings only through schooling.
The child labor law IV (Strategy 3) and the DiD approach exploit the same underlying variation — policy changes in compulsory schooling laws across states and time. Both give similar estimates, reinforcing the causal interpretation.
The Furious Five: A Grand Synthesis
This chapter has applied all five methods from the book to a single question. Each method can be summarized by its key equation, all targeting the same parameter \(\rho\) — the causal return to schooling:
| Method | Key Equation |
|---|---|
| Bivariate OLS | \(\ln W_i = \alpha + \rho \, S_i + e_i\) |
| OLS with controls | \(\ln W_i = \alpha + \rho \, S_i + \gamma' X_i + e_i\) |
| Twin FE | \(\Delta Y_f = \rho \, \Delta S_f + \Delta e_f\) |
| IV (Wald) | \(\hat{\rho}_{IV} = \hat{\rho}_{RF} \, / \, \hat{\phi}\) |
| 2SLS | Stage 1: \(S_i = \pi_0 + \pi_1 Z_i + v_i\); Stage 2: \(\ln W_i = \alpha + \rho_{IV} \hat{S}_i + u_i\) |
| RD | \(Y_i = \alpha + \rho \, D_i + f(\text{Score}_i) + e_i\) |
| DD | \(Y_{st} = \alpha + \delta \, (\text{Treated}_s \times \text{Post}_t) + \beta_s + \gamma_t + e_{st}\) |
| Method | Key Assumption | What It Estimates | Main Threat | Used Here? |
|---|---|---|---|---|
| 1. RCT | Random assignment | ATE | Non-compliance | Synthetic demo |
| 2. Regression | Observable confounders only | Conditional average | OVB (ability bias) | Yes (OLS baseline) |
| 3. IV / 2SLS | Valid instrument | LATE (compliers) | Weak/invalid instrument | Yes (twins, QOB, child labor) |
| 4. RD | Smooth running variable | Local effect at cutoff | Limited generalizability | Yes (sheepskin) |
| 5. DD | Parallel trends | ATT | Pre-trend violation | Synthetic demo |
What Is the True Return to Schooling?
| Method | Estimate | Main Bias | Direction |
|---|---|---|---|
| Simple OLS (no controls) | ~0.07 | Ability bias (OVB) | Likely upward |
| OLS with controls | ~0.11 | Unobserved ability | Upward |
| Twin FE | ~0.06 | Measurement error | Downward |
| Twin IV | ~0.11 | Corrects measurement error | — |
| Quarter-of-birth IV | ~0.07–0.08 | LATE for compliers only | — |
| Child labor law IV | ~0.07–0.13 | Weak instruments, imprecise | — |
| Sheepskin RD | ~0 | Diploma effect specifically | — |
| DD (synthetic) | ~0.06 | Parallel trends required | — |
NoteThe big picture
The true causal return to schooling is probably 7–10% per year. OLS slightly overstates it (ability bias), while twin FE understates it (measurement error). The IV estimates cluster around 7–10%. The near-zero sheepskin effect suggests that the return comes from actual learning, not credential signaling.
No single method is perfect. The power of this chapter lies in seeing how multiple imperfect strategies converge on a similar answer.
Why this matters for policy. Multiple methods converge: twins, quarter of birth, and compulsory schooling laws all point to a genuine causal return of 7–10% per year. Education is one of the best investments individuals and governments can make — and the return comes from actual learning, not just the diploma.
Key Takeaways
graph TD
Q["Does education cause higher earnings?"]
AB["Ability bias inflates simple OLS"]
OVB["OVB formula: bias equals gamma times pi"]
RCT["RCT is ideal but infeasible"]
TW["Twin FE removes shared ability"]
ME["Measurement error biases twins down"]
IV["IV corrects both biases"]
RD["Sheepskin RD: diploma effect is small"]
DD["DD: policy changes confirm returns"]
SYN["Synthesis: true return is about seven to ten percent"]
Q --> AB
AB --> OVB
OVB --> RCT
RCT --> TW
TW --> ME
ME --> IV
Q --> RD
Q --> DD
TW --> SYN
IV --> SYN
RD --> SYN
DD --> SYN
style Q fill:#2c3e50,color:#fff
style AB fill:#c0392b,color:#fff
style OVB fill:#e67e22,color:#fff
style RCT fill:#3498db,color:#fff
style TW fill:#8e44ad,color:#fff
style ME fill:#c0392b,color:#fff
style IV fill:#3498db,color:#fff
style RD fill:#2d8659,color:#fff
style DD fill:#2d8659,color:#fff
style SYN fill:#2d8659,color:#fff
linkStyle 0,1,2,3,4,5,6,7,8,9,10 stroke:#888,stroke-width:2px
Simple OLS returns to schooling (~7%) reflect both the causal effect and selection bias (ability bias), so they overstate the true causal return.
The OVB formula predicts upward bias: ability raises both schooling and earnings.
RCTs are the gold standard but infeasible for schooling — motivating quasi-experimental methods.
OLS with controls (~11%) on the twins data shows that demographic controls do not substantially reduce the schooling coefficient.
Twin fixed effects (~6%) control for shared ability but suffer from measurement error amplification.
IV using twin’s report (~11%) corrects measurement error, recovering a higher estimate.
Quarter-of-birth IV (~7%) uses compulsory schooling as exogenous variation, estimating a LATE for dropout-margin students.
Child labor law IV (~7–10%) uses a different set of instruments, confirming the QOB results.
Sheepskin RD (~0%) shows the diploma itself has little earnings value — learning matters more.
DD exploiting policy changes (~8%) provides yet another perspective using before/after comparisons.
Multiple methods converge on a true return of about 7–10% per year.
No single method is perfect. The lesson is to use multiple approaches and look for convergence.
Learn by Coding
Copy this code into a Python notebook to reproduce the key results from this chapter.
# ============================================================
# Chapter 6: The Wages of Schooling — Code Cheatsheet
# ============================================================
import pandas as pd
import numpy as np
import pyfixest as pf
# (IV handled by pf.feols with pipe syntax)
DATA = "https://raw.githubusercontent.com/cmg777/intro2causal/main/data/"
# --- Step 1: Simple bivariate OLS (no controls) ---
qob = pd.read_csv(DATA + "ch6/qob_clean.csv")
bivariate = pf.feols("lnw ~ s", data=qob, vcov="hetero")
print(f"Simple OLS return: {round(bivariate.coef()['s'], 3)} ({round(bivariate.se()['s'], 3)})")
print(" (~7% per year — raw correlation, likely biased by ability)\n")
# --- Step 2: OLS with controls (twins data) ---
twins = pd.read_csv(DATA + "ch6/twins_clean.csv")
ols_result = pf.feols("lwage ~ educ + age + age2 + female + white", data=twins, vcov="hetero")
print(f"OLS with controls: {round(ols_result.coef()['educ'], 3)} ({round(ols_result.se()['educ'], 3)})")
print(" (~11% per year — controls barely change the estimate)\n")
# --- Step 3: Twin fixed effects (within-pair differences) ---
first = twins[twins["first"] == 1]
fe = pf.feols("dlwage ~ deduc - 1", data=first, vcov="hetero")
print(f"Twin FE return: {round(fe.coef()['deduc'], 3)} ({round(fe.se()['deduc'], 3)})")
print(" (~6% — lower because shared ability is removed, but measurement error amplified)\n")
# --- Step 4: IV with twin's report (corrects measurement error) ---
iv_lev = pf.feols("lwage ~ 1 + age + age2 + female + white | educ ~ educt_t", data=twins, vcov="hetero")
print(f"Twin IV (levels): {round(iv_lev.coef()['educ'], 3)} ({round(iv_lev.se()['educ'], 3)})")
print(" (~11% — measurement error corrected)\n")
# --- Step 5: Quarter-of-birth IV (Angrist & Krueger) ---
fs = pf.feols("s ~ q4", data=qob, vcov="hetero")
rf = pf.feols("lnw ~ q4", data=qob, vcov="hetero")
wald = rf.coef()["q4"] / fs.coef()["q4"]
print(f"Wald IV estimate: {round(wald, 3)}")
iv_qob = pf.feols("lnw ~ 1 | s ~ q4", data=qob, vcov="hetero")
print(f"2SLS estimate: {round(iv_qob.coef()['s'], 3)} ({round(iv_qob.se()['s'], 3)})")
print(" (~7% per year via quarter-of-birth instrument)\n")
# --- Step 6: Child labor law IV ---
cl = pd.read_csv(DATA + "ch6/childlabor_clean.csv")
ols_cl = pf.feols("lnwkwage ~ indEduc | sob + yob + year",
data=cl, weights="weight", vcov={"CRV1": "sob"})
print(f"OLS (child labor data): {round(ols_cl.coef()['indEduc'], 4)}")
# --- Step 7: First-stage F-statistic ---
f_stat = fs.tstat()['q4'] ** 2 # F = t² for a single restriction
print(f"First-stage F-stat (QOB): {round(f_stat, 1)} (should be > 10)")
TipTry it yourself!
Copy the code above and paste it into this Google Colab scratchpad to run it interactively. Modify the variables, change the specifications, and see how results change!
Below is the same cheatsheet in Stata syntax.
* ============================================================
* Chapter 6: The Wages of Schooling — Stata Cheatsheet
* ============================================================
clear all
set more off
* --- Step 1: Simple bivariate OLS (no controls) ---
import delimited using "https://raw.githubusercontent.com/cmg777/intro2causal/main/data/ch6/qob_clean.csv", clear
reg lnw s, robust
* ~7% per year — raw correlation, likely biased by ability
* --- Step 2: OLS with controls (twins data) ---
import delimited using "https://raw.githubusercontent.com/cmg777/intro2causal/main/data/ch6/twins_clean.csv", clear
reg lwage educ age age2 female white, robust
* ~11% per year — controls barely change the estimate
* --- Step 3: Twin fixed effects (within-pair differences) ---
reg dlwage deduc if first == 1, noconstant robust
* ~6% — lower because shared ability is removed
* --- Step 4: IV with twin's report ---
ivregress 2sls lwage age age2 female white (educ = educt_t), robust
* ~11% — measurement error corrected
* --- Step 5: Quarter-of-birth IV (Angrist & Krueger) ---
import delimited using "https://raw.githubusercontent.com/cmg777/intro2causal/main/data/ch6/qob_clean.csv", clear
* First stage
reg s q4, robust
scalar fs_coef = _b[q4]
* Reduced form
reg lnw q4, robust
scalar rf_coef = _b[q4]
* Wald IV estimate
scalar wald = rf_coef / fs_coef
display "Wald IV estimate: " round(wald, 0.001)
* 2SLS
ivregress 2sls lnw (s = q4), robust
* ~7% per year via quarter-of-birth instrument
* --- Step 6: Child labor law IV ---
import delimited using "https://raw.githubusercontent.com/cmg777/intro2causal/main/data/ch6/childlabor_clean.csv", clear
reg indeduc cl7 cl8 cl9 i.sob i.yob i.year [aw=weight], cluster(sob)
testparm cl7 cl8 cl9
ivregress 2sls lnwkwage i.sob i.yob i.year (indeduc = cl7 cl8 cl9) [aw=weight], cluster(sob)
TipTry it in Stata!
Copy the code above into a .do file and run it in Stata 14 or later (which supports loading data from URLs). If your Stata cannot access the internet, download the CSV files from the data/ folder on GitHub and replace each URL with a local file path.
The Furious Five: A Code Summary
The Furious Five are the five core methods of causal inference covered in Mastering ’Metrics. Each method tackles the same fundamental problem — separating cause from correlation — but relies on a different source of identifying variation and a different key assumption.
| Method | Key Assumption | What It Estimates | Main Threat |
|---|---|---|---|
| 1. RCT | Random assignment of treatment | ATE (Average Treatment Effect) | Non-compliance, spillovers |
| 2. Regression (OLS) | All confounders observed and controlled | Conditional average effect | Omitted variable bias |
| 3. IV / 2SLS | Valid instrument (relevance + exclusion) | LATE (effect for compliers) | Weak or invalid instrument |
| 4. RD | No manipulation of running variable | Local effect at the cutoff | Limited external validity |
| 5. DD | Parallel trends absent treatment | ATT (effect on the treated) | Pre-trend differences |
Tippyfixest syntax and intuitive analogies for each method
| Method | pyfixest Syntax | Intuitive Analogy |
|---|---|---|
| RCT | group_means = df.groupby("D")["Y"].mean() |
A coin flip decides who gets the medicine — any difference in health must be caused by it |
| OLS | pf.feols("Y ~ D + X", data=df, vcov="hetero") |
Adjusting marathon times for weather and elevation — helpful if you measure everything, but miss one factor and the comparison is off |
| IV | pf.feols("Y ~ 1 \| D ~ Z", data=df, vcov="hetero") |
Using rainfall to study how carrying an umbrella affects your mood — rain shifts umbrella use but does not directly change mood |
| RD | pf.feols("Y ~ D * score", data=df, vcov="hetero") |
Comparing students who scored 59 vs. 61 on a pass/fail exam — nearly identical except for the credential |
| DD | pf.feols("Y ~ treat_post \| group + time", data=df, vcov={"CRV1": "group"}) |
Two cities track the same crime trend until one adopts a new policy — the divergence is the causal effect |
When the Furious Five agree, we gain confidence. No single method is bulletproof, but when multiple methods — each with different data, assumptions, and potential biases — all point to a similar answer, the finding becomes much more credible. This chapter showed exactly that: the true causal return to schooling is about 7–10% per year, confirmed across all five methods.
WarningCode is not a substitute for understanding
The code below is a stylized overview of the Furious Five — a compact reference to remind you what each method does. But applying these methods should never be mechanical. Each method rests on assumptions that must be justified by the context in which the data was collected and the relationships that economic theory suggests. A valid instrument in one setting may be invalid in another. Parallel trends may hold in one policy comparison but fail in the next. Before running any of these methods, carefully study the relevant chapter of the book to understand when and why each method works — not just how to code it.
Below is a self-contained code summary that applies each of the Furious Five to the returns-to-schooling question using the datasets from this chapter.
# ================================================================
# THE FURIOUS FIVE — Complete Code Summary
# ================================================================
# Five methods, one question: Does education cause higher earnings?
# Each block is self-contained with its own data, equation, and
# interpretation. Run them all to see convergence in action.
# ================================================================
import pandas as pd
import numpy as np
import pyfixest as pf
# (IV handled by pf.feols with pipe syntax)
DATA = "https://raw.githubusercontent.com/cmg777/intro2causal/main/data/"
# ================================================================
# METHOD 1: RANDOMIZED CONTROLLED TRIAL (WITH NON-COMPLIANCE)
# ================================================================
# Question: Does education cause higher earnings?
# Equation: ln(W) = α + ρ·S + ε (First Stage: S = γ_0 + γ_1·Z + u)
# Logic: Z (scholarship offer) is randomly assigned. We use it to
# isolate exogenous variation in S (actual schooling).
# Estimate: Wald ratio = (Reduced Form effect on W) / (First Stage effect on S)
# Bias: None, assuming the offer only affects earnings through schooling
# ----------------------------------------------------------------
rct = pd.read_csv(DATA + "ch6/synthetic_rct.csv")
means = rct.groupby("scholarship")[["schooling", "earnings"]].mean()
wald_rct = (means.loc[1, "earnings"] - means.loc[0, "earnings"]) / \
(means.loc[1, "schooling"] - means.loc[0, "schooling"])
print(f"1. RCT (Wald): {wald_rct:.4f}")
# ================================================================
# METHOD 2: REGRESSION (OLS)
# ================================================================
# Question: What is the raw return to each year of schooling?
# Equation: ln(W) = α + ρ·S + ε
# Logic: Control for observables, hoping all confounders are captured.
# Estimate: Conditional average association (not necessarily causal).
# Bias: Omitted Variable Bias (e.g., Ability Bias - upward). Smarter
# individuals may get more schooling AND earn more regardless.
# ----------------------------------------------------------------
qob = pd.read_csv(DATA + "ch6/qob_clean.csv")
ols = pf.feols("lnw ~ s", data=qob, vcov="hetero")
print(f"2. OLS: {ols.coef()['s']:.4f}")
# ================================================================
# METHOD 3: INSTRUMENTAL VARIABLES (IV / 2SLS)
# ================================================================
# Question: What is the causal return to schooling, using exogenous variation?
# Equation: Wald = Cov(Y, Z) / Cov(D, Z)
# Logic: Quarter of birth (Z) shifts schooling laws but is unrelated to ability.
# Estimate: LATE — Local Average Treatment Effect for "compliers"
# (students kept in school solely due to compulsory schooling laws).
# Bias: None, provided Z is relevant and the exclusion restriction holds.
# ----------------------------------------------------------------
iv = pf.feols("lnw ~ 1 | s ~ q4", data=qob, vcov="hetero")
print(f"3. IV (QOB): {iv.coef()['s']:.4f}")
# ================================================================
# METHOD 4: REGRESSION DISCONTINUITY (RD)
# ================================================================
# Question: Does the diploma credential itself boost earnings?
# Equation: Y = α + ρ·D + β_1·(Score) + β_2·(D × Score) + ε
# Logic: Compare students just above vs. just below the passing cutoff.
# Estimate: LATE at the cutoff (the "sheepskin" or credential effect).
# Bias: None, assuming continuity of potential outcomes at the cutoff
# (students cannot precisely manipulate their scores).
# ----------------------------------------------------------------
sheep = pd.read_csv(DATA + "ch6/sheepskin_clean.csv")
# Center the running variable if not already centered, and apply a bandwidth (e.g., +/- 30)
bandwidth_data = sheep[abs(sheep["minscore"]) <= 30]
# Use robust local linear regression allowing varying slopes on either side of cutoff
rd = pf.feols("avgearnings ~ pass_exam * minscore", data=bandwidth_data, weights="person_years", vcov="hetero")
print(f"4. RD: ${rd.coef()['pass_exam']:.0f} (Credential effect)")
# ================================================================
# METHOD 5: DIFFERENCES-IN-DIFFERENCES (WALD-DiD)
# ================================================================
# Question: Do compulsory schooling reforms (T) raise causal earnings?
# Equation: Wald-DiD = DiD_Earnings / DiD_Schooling
# Logic: Compare changes over time in reform vs. non-reform states, using
# the reform as an instrument for actual years of schooling.
# Estimate: LATE of schooling on earnings driven by the policy change.
# Bias: Biased if parallel trends assumption fails (states would have
# had different trajectories absent the reform).
# ----------------------------------------------------------------
did = pd.read_csv(DATA + "ch6/synthetic_did.csv")
did["treat_post"] = did["treated"] * did["post"]
# First stage: Effect of policy on schooling
dd_s = pf.feols("avg_schooling ~ treat_post | state + year", data=did, vcov={"CRV1": "state"})
# Reduced form: Effect of policy on earnings
dd_e = pf.feols("avg_earnings ~ treat_post | state + year", data=did, vcov={"CRV1": "state"})
wald_did = dd_e.coef()['treat_post'] / dd_s.coef()['treat_post']
print(f"5. Wald-DiD: {wald_did:.4f}")Below is the same Furious Five summary in Stata syntax.
* =================================================================
* THE FURIOUS FIVE — Complete Code Summary (Stata)
* =================================================================
* Five methods, one question: Does education cause higher earnings?
* =================================================================
clear all
set more off
* =================================================================
* METHOD 1: RANDOMIZED CONTROLLED TRIAL (WITH NON-COMPLIANCE)
* =================================================================
* Question: Does education cause higher earnings?
* Equation: ln(W) = a + rho*S + e (First Stage: S = g0 + g1*Z + u)
* Logic: Z (scholarship offer) is randomly assigned. We use it to
* isolate exogenous variation in S (actual schooling).
* Estimate: Wald ratio = (Reduced Form effect on W) / (First Stage effect on S)
* Bias: None, assuming the offer only affects earnings through schooling
* -----------------------------------------------------------------
import delimited using ///
"https://raw.githubusercontent.com/cmg777/intro2causal/main/data/ch6/synthetic_rct.csv", clear
* Manual Wald calculation for pedagogical clarity
quietly reg earnings scholarship, robust
scalar rf = _b[scholarship]
quietly reg schooling scholarship, robust
scalar fs = _b[scholarship]
display "1. RCT (Wald): " round(rf / fs, 0.0001)
* Note: In practice, we estimate this directly via 2SLS to get correct standard errors:
* ivregress 2sls earnings (schooling = scholarship), robust
* =================================================================
* METHOD 2: REGRESSION (OLS)
* =================================================================
* Question: What is the raw return to each year of schooling?
* Equation: ln(W) = a + rho*S + e
* Logic: Control for observables, hoping all confounders are captured.
* Estimate: Conditional average association (not necessarily causal).
* Bias: Omitted Variable Bias (e.g., Ability Bias - upward). Smarter
* individuals may get more schooling AND earn more regardless.
* -----------------------------------------------------------------
import delimited using ///
"https://raw.githubusercontent.com/cmg777/intro2causal/main/data/ch6/qob_clean.csv", clear
reg lnw s, robust
* =================================================================
* METHOD 3: INSTRUMENTAL VARIABLES (IV / 2SLS)
* =================================================================
* Question: What is the causal return to schooling, using exogenous variation?
* Equation: Wald = Cov(Y, Z) / Cov(D, Z)
* Logic: Quarter of birth (Z) shifts schooling laws but is unrelated to ability.
* Estimate: LATE -- Local Average Treatment Effect for "compliers"
* (students kept in school solely due to compulsory schooling laws).
* Bias: None, provided Z is relevant and the exclusion restriction holds.
* -----------------------------------------------------------------
ivregress 2sls lnw (s = q4), robust
* =================================================================
* METHOD 4: REGRESSION DISCONTINUITY (RD)
* =================================================================
* Question: Does the diploma credential itself boost earnings?
* Equation: Y = a + rho*D + b1*(Score) + b2*(D x Score) + e
* Logic: Compare students just above vs. just below the passing cutoff.
* Estimate: LATE at the cutoff (the "sheepskin" or credential effect).
* Bias: None, assuming continuity of potential outcomes at the cutoff
* (students cannot precisely manipulate their scores).
* -----------------------------------------------------------------
import delimited using ///
"https://raw.githubusercontent.com/cmg777/intro2causal/main/data/ch6/sheepskin_clean.csv", clear
* Interact treatment with the running variable to allow different slopes
gen pass_X_score = pass_exam * minscore
* Local linear regression using a rectangular kernel (bandwidth of +/- 30)
reg avgearnings pass_exam minscore pass_X_score ///
if abs(minscore) <= 30 [aw = person_years], robust
* =================================================================
* METHOD 5: DIFFERENCES-IN-DIFFERENCES (WALD-DiD)
* =================================================================
* Question: Do compulsory schooling reforms (T) raise causal earnings?
* Equation: Wald-DiD = DiD_Earnings / DiD_Schooling
* Logic: Compare changes over time in reform vs. non-reform states, using
* the reform as an instrument for actual years of schooling.
* Estimate: LATE of schooling on earnings driven by the policy change.
* Bias: Biased if parallel trends assumption fails (states would have
* had different trajectories absent the reform).
* -----------------------------------------------------------------
import delimited using ///
"https://raw.githubusercontent.com/cmg777/intro2causal/main/data/ch6/synthetic_did.csv", clear
gen treat_post = treated * post
* First stage: Effect of policy on schooling
quietly reg avg_schooling treat_post i.state i.year, cluster(state)
scalar dd_fs = _b[treat_post]
* Reduced form: Effect of policy on earnings
quietly reg avg_earnings treat_post i.state i.year, cluster(state)
display "5. Wald-DD: " round(_b[treat_post] / dd_fs, 0.0001)Exercises
Multiple Choice Questions
- In the simple bivariate regression of earnings on schooling, the estimated return is about 7%. This estimate is likely:
- Too low because it ignores the earnings premium for higher-status jobs
- Too high because unobserved ability inflates the correlation between schooling and earnings
- Exactly right because the sample is very large
- Too low because measurement error biases the coefficient downward
NoteShow answer
(b) The simple bivariate OLS captures both the causal return to schooling and the spurious correlation driven by ability. Since more able people tend to get more schooling AND earn more, OLS conflates these effects, overstating the causal return.
- The OVB formula predicts that omitting ability from the schooling regression will bias the coefficient upward because:
- Ability is negatively correlated with schooling
- Ability has a negative effect on earnings
- Both the correlation of ability with schooling and the effect of ability on earnings are positive
- Ability is uncorrelated with education in the population
NoteShow answer
(c) The OVB formula says bias = \(\gamma \times \pi_1\). Both are positive: ability raises earnings (\(\gamma > 0\)) and ability raises schooling (\(\pi_1 > 0\)). So the product is positive, meaning OLS overstates the causal return.
- The main econometric challenge in estimating the return to schooling is:
- Education data is poorly measured
- Unobserved ability may be correlated with both education and earnings (ability bias)
- The return to schooling varies across countries
- Schooling has no effect on earnings
NoteShow answer
(b) The core challenge is ability bias: people with higher unobserved ability tend to get more education AND earn more, regardless of schooling. This makes the OLS estimate overstate the causal effect.
- The twin fixed-effects strategy controls for ability bias by:
- Including IQ test scores as a control variable
- Comparing earnings differences within identical twin pairs who share the same genes and family background
- Using random assignment to determine who attends college
- Restricting the sample to people with above-average ability
NoteShow answer
(b) Identical twins share genetics and family environment — the key sources of ability differences. By comparing earnings within twin pairs, the strategy differences out shared ability.
- The twin FE estimate (6%) is lower than OLS (11%). This is MOST likely because:
- The twin FE definitively proves the true return is 6%
- Measurement error in self-reported education is amplified by differencing, biasing the estimate downward
- Twins are not representative of the general population
- OLS is always biased upward
NoteShow answer
(b) When twins report their own education, small errors are amplified by differencing because the true within-pair variation is small relative to the noise. This attenuation bias pushes the twin FE estimate below the true return.
- Angrist and Krueger’s quarter-of-birth instrument works because:
- People born in different quarters have different levels of ability
- Compulsory schooling laws interact with birth quarter to create exogenous variation in years of education
- Employers pay more to workers born in certain quarters
- Season of birth directly affects earnings through health channels
NoteShow answer
(b) Students born in Q4 enter school at a younger age, so by the time they reach the legal dropout age (e.g., 16), they have completed more years of schooling than those born in Q1. Compulsory schooling laws create exogenous variation in education unrelated to ability.
- A “sheepskin effect” refers to:
- The return to each additional year of schooling
- A discrete jump in earnings at diploma/degree completion, beyond the effect of the extra year
- The effect of attending a prestigious university
- The bias introduced by omitting ability from the regression
NoteShow answer
(b) A sheepskin effect is the extra earnings bump from completing a degree. The Clark and Martorell RD showed the diploma itself had almost no effect on earnings, suggesting most of the education premium comes from actual learning.
- Controlling for occupation when estimating the return to schooling is problematic because:
- Occupation data is measured with too much error
- Occupation is caused by education (a post-treatment variable), so controlling for it absorbs part of the causal effect
- Occupation is uncorrelated with earnings
- There are too many occupation categories for the regression to handle
NoteShow answer
(b) Occupation is caused by education — it is a “bad control” (post-treatment variable). Controlling for it absorbs part of the causal effect: if education raises earnings partly by giving access to better jobs, holding occupation constant removes that channel.
- The child labor law IV estimates are useful because they:
- Use random assignment to determine schooling
- Provide an independent source of exogenous variation from a different set of instruments than quarter of birth
- Eliminate measurement error in education
- Estimate the average treatment effect for the entire population
NoteShow answer
(b) The child labor law instruments provide variation that is independent of QOB, using different policy mechanisms. This independent confirmation strengthens causal claims.
- In a differences-in-differences analysis of compulsory schooling reforms, the key identifying assumption is:
- States that adopted the reform are identical to those that did not
- In the absence of the reform, treated and control states would have followed the same trend in outcomes
- The reform was randomly assigned to states
- All individuals in treated states complied with the new law
NoteShow answer
(b) The key DD assumption is that in the absence of the reform, treated and control states would have followed the same trajectory. This is the parallel trends assumption.
Conceptual Questions
- Ability bias direction: A friend argues that ability bias could go downward (smart people drop out to start businesses). Give one example supporting this view and one supporting the standard upward-bias view. Which do you find more convincing for the general population?
NoteShow answer
Ability bias is upward for most people because the education system selects on ability, but rare high-ability dropouts illustrate the theoretical possibility of downward bias.
- Downward bias example: Mark Zuckerberg dropped out of Harvard to build Facebook and became a billionaire. His high ability generated high earnings without completing his degree.
- Upward bias example: A student with high IQ and supportive parents completes a PhD and earns a high salary. OLS conflates the ability effect with the schooling effect.
- For the general population, upward bias is far more convincing: the education system systematically selects on ability through grades, test scores, and admissions.
- Measurement error: Explain why measurement error in education is more problematic in the twin-differences specification than in the levels OLS. (Hint: think about what differencing does to the signal-to-noise ratio.)
NoteShow answer
Differencing within twin pairs amplifies measurement error because it shrinks the true signal while leaving the noise unchanged.
- Measurement error adds noise (\(m_i\)) to observed schooling: \(S_i = S_i^* + m_i\).
- In levels OLS, the reliability ratio \(r = \text{Var}(S^*) / [\text{Var}(S^*) + \text{Var}(m)]\) is close to 1 because schooling varies widely.
- Differencing shrinks \(\text{Var}(\Delta S^*)\) dramatically but \(\text{Var}(\Delta m)\) stays the same. The reliability ratio \(r\) falls sharply, and attenuation bias worsens.
- This is why the twin FE estimate (~0.06) is lower than OLS (~0.11). The IV correction using the co-twin’s report recovers the true return.
- The Wald estimate: Using the QOB data, the reduced form (Q4 → earnings) is 0.0068 and the first stage (Q4 → schooling) is 0.0921. (a) Compute the Wald/IV estimate. (b) Why is this estimate valid only for “compliers”? Who are the compliers in this context?
NoteShow answer
The Wald/IV estimate identifies a LATE of about 7.4% per year, but it applies only to the marginal students whose schooling was changed by compulsory schooling laws.
- Wald estimate = 0.0068 / 0.0921 = 0.074, or about 7.4% per year.
- This is a LATE — it applies only to compliers whose schooling was changed by their quarter of birth interacting with compulsory schooling laws.
- Compliers are students at the dropout threshold. Always-takers (college-bound) and never-takers (very early dropouts) are not affected.
- OLS vs. IV similarity: In the QOB analysis, OLS and IV give similar estimates (~0.07). Does this mean ability bias is small? Or could there be offsetting biases (one pushing up, one pushing down) that happen to cancel? Explain.
NoteShow answer
The similarity of OLS and IV estimates is a coincidence of two offsetting biases, not evidence that OLS is unbiased.
- OLS is biased upward by ability bias and downward by measurement error.
- IV corrects both simultaneously. The net result happens to land close to OLS.
- The twin evidence confirms: IV with the co-twin’s report raises the estimate above twin FE; twin FE without IV falls below OLS. Each bias is real.
- Sheepskin interpretation: The Texas RD shows a ~40 percentage point jump in diploma receipt but near-zero earnings effect. A skeptic says “this proves education doesn’t matter.” Explain why this conclusion is wrong. What does the sheepskin RD actually tell us about the mechanism through which education raises earnings?
NoteShow answer
The sheepskin RD proves the diploma itself has little independent value, implying that the large education premium comes from actual learning.
- The Texas RD compares students who barely passed vs. barely failed. The near-zero earnings difference shows credentialism is not the main driver.
- This separates human capital theory from signaling theory. The small sheepskin effect supports human capital.
- Education clearly raises earnings — the finding tells us why (skills, not signals) rather than whether.
- OVB formula: Using the synthetic OVB dataset, the short regression gives ~0.12 and the long regression gives ~0.09. Apply the OVB formula: what are the signs of \(\gamma\) (ability → earnings) and \(\pi_1\) (ability → schooling)? Is the bias direction consistent with what you observe?
NoteShow answer
Both \(\gamma > 0\) (ability raises earnings) and \(\pi_1 > 0\) (ability raises schooling). OVB = \(\gamma \times \pi_1 > 0\), matching the pattern: short regression (~0.12) overstates the true return (~0.09) by about 0.03.
- Bad controls vs. good controls: Explain the difference between controlling for age (a good control) and controlling for occupation (a bad control) when estimating returns to schooling. What determines whether a control variable is “good” or “bad”?
NoteShow answer
Age is determined before schooling decisions — it is a pre-treatment variable. Occupation is caused by education — it is post-treatment. Controlling for occupation removes part of the causal pathway (education → better job → higher earnings). The rule: a control is “good” if determined before the treatment, “bad” if it is a consequence.
Research Tasks
- Returns for men only: Using
twins_clean.csv, restrict the sample to male twins (female == 0). Re-run the OLS and within-twin FE regressions. Do the returns to schooling differ for men compared to the full sample?
NoteShow answer
Code
# --- Full Sample: OLS and Twin FE ---
ols_all = pf.feols("lwage ~ educ + age + age2 + female + white", data=twins, vcov="hetero")
first_all = twins[twins["first"] == 1]
fe_all = pf.feols("dlwage ~ deduc - 1", data=first_all, vcov="hetero")
# --- Men Only: OLS and Twin FE ---
men = twins[twins["female"] == 0]
ols_men = pf.feols("lwage ~ educ + age + age2 + white", data=men, vcov="hetero")
first_men = men[men["first"] == 1]
fe_men = pf.feols("dlwage ~ deduc - 1", data=first_men, vcov="hetero")
pd.DataFrame({
"Method": ["OLS (full sample)", "OLS (men only)", "Twin FE (full sample)", "Twin FE (men only)"],
"Coefficient": [
round(ols_all.coef()["educ"], 4), round(ols_men.coef()["educ"], 4),
round(fe_all.coef()["deduc"], 4), round(fe_men.coef()["deduc"], 4),
],
"SE": [
round(ols_all.se()["educ"], 4), round(ols_men.se()["educ"], 4),
round(fe_all.se()["deduc"], 4), round(fe_men.se()["deduc"], 4),
],
"N": [int(ols_all._N), int(ols_men._N), int(fe_all._N), int(fe_men._N)],
})| Method | Coefficient | SE | N | |
|---|---|---|---|---|
| 0 | OLS (full sample) | 0.1100 | 0.0105 | 680 |
| 1 | OLS (men only) | 0.1017 | 0.0186 | 274 |
| 2 | Twin FE (full sample) | 0.0617 | 0.0198 | 340 |
| 3 | Twin FE (men only) | 0.0630 | 0.0330 | 136 |
Stata equivalent:
* --- Returns to schooling: full sample vs. men only ---
clear all
set more off
import delimited using "https://raw.githubusercontent.com/cmg777/intro2causal/main/data/ch6/twins_clean.csv", clear
reg lwage educ age age2 female white, robust
reg dlwage deduc if first == 1, robust noconstant
reg lwage educ age age2 white if female == 0, robust
reg dlwage deduc if first == 1 & female == 0, robust noconstantThe key pattern — OLS exceeding twin FE — should persist in both samples.
- Multiple instruments: Using
qob_clean.csv, run the 2SLS regression using all three quarter dummies (q2,q3,q4) as instruments for schooling instead of justq4. Does the IV estimate change? How does the first-stage F-statistic compare?
NoteShow answer
Code
iv_q4 = pf.feols("lnw ~ 1 | s ~ q4", data=qob, vcov="hetero")
fs_q4 = pf.feols("s ~ q4", data=qob)
f_q4 = fs_q4.tstat()['q4'] ** 2 # F = t² for single restriction
iv_multi = pf.feols("lnw ~ 1 | yob | s ~ q2 + q3 + q4", data=qob, vcov="hetero")
fs_multi = pf.feols("s ~ q2 + q3 + q4 | yob", data=qob)
t_q2 = fs_multi.tstat()["q2"]
t_q3 = fs_multi.tstat()["q3"]
t_q4_m = fs_multi.tstat()["q4"]
f_multi = (t_q2**2 + t_q3**2 + t_q4_m**2) / 3 # approximate joint F
pd.DataFrame({
"Specification": ["IV (Q4 only, no controls)", "IV (Q2+Q3+Q4, with YOB FE)"],
"Return to schooling": [round(iv_q4.coef()["s"], 4), round(iv_multi.coef()["s"], 4)],
"SE": [round(iv_q4.se()["s"], 4), round(iv_multi.se()["s"], 4)],
"First-stage F": [round(f_q4, 1), round(f_multi, 1)],
})| Specification | Return to schooling | SE | First-stage F | |
|---|---|---|---|---|
| 0 | IV (Q4 only, no controls) | 0.0740 | 0.0280 | 48.1 |
| 1 | IV (Q2+Q3+Q4, with YOB FE) | 0.1053 | 0.0201 | 48.5 |
Stata equivalent:
* --- IV: single vs. multiple instruments ---
clear all
set more off
import delimited using "https://raw.githubusercontent.com/cmg777/intro2causal/main/data/ch6/qob_clean.csv", clear
ivregress 2sls lnw (s = q4), robust
reg s q4, robust
test q4
tab yob, gen(yob_)
ivregress 2sls lnw yob_* (s = q2 q3 q4), robust
reg s q2 q3 q4 yob_*, robust
test q2 q3 q4Multiple instruments gain precision but require all to satisfy the exclusion restriction.
- White vs. non-white twins: Using
twins_clean.csv, split the sample bywhitestatus and run the OLS regression for each group. Is the return to schooling different for white vs. non-white twins?
NoteShow answer
Code
rows = []
for race, label in [(1, "White"), (0, "Non-white")]:
subset = twins[twins["white"] == race]
if len(subset) > 10:
r = pf.feols("lwage ~ educ + age + age2 + female", data=subset, vcov="hetero")
rows.append({
"Group": label,
"OLS return": round(r.coef()["educ"], 4),
"SE": round(r.se()["educ"], 4),
"N": int(r._N),
})
pd.DataFrame(rows)| Group | OLS return | SE | N | |
|---|---|---|---|---|
| 0 | White | 0.1108 | 0.0109 | 623 |
| 1 | Non-white | 0.0985 | 0.0360 | 53 |
Stata equivalent:
* --- Returns to schooling by race ---
clear all
set more off
import delimited using "https://raw.githubusercontent.com/cmg777/intro2causal/main/data/ch6/twins_clean.csv", clear
reg lwage educ age age2 female if white == 1, robust
reg lwage educ age age2 female if white == 0, robustSeveral factors could drive racial differences: labor market discrimination, school quality differences, and occupational sorting.
- OLS vs. IV comparison: Using
qob_clean.csv, compare the OLS and IV (2SLS with Q4 as instrument) estimates of the return to schooling. Are the estimates similar? What does the comparison tell you about offsetting biases?
NoteShow answer
Code
# --- OLS: naive regression ---
ols = pf.feols("lnw ~ s", data=qob, vcov="hetero")
# --- IV: 2SLS with Q4 as instrument ---
iv = pf.feols("lnw ~ 1 | s ~ q4", data=qob, vcov="hetero")
pd.DataFrame({
"Method": ["OLS", "IV (2SLS, Q4 instrument)"],
"Return to schooling": [round(ols.coef()["s"], 4), round(iv.coef()["s"], 4)],
"SE": [round(ols.se()["s"], 4), round(iv.se()["s"], 4)],
})| Method | Return to schooling | SE | |
|---|---|---|---|
| 0 | OLS | 0.0709 | 0.0004 |
| 1 | IV (2SLS, Q4 instrument) | 0.0740 | 0.0280 |
Stata equivalent:
* --- OLS vs. IV for returns to schooling ---
clear all
set more off
import delimited using "https://raw.githubusercontent.com/cmg777/intro2causal/main/data/ch6/qob_clean.csv", clear
reg lnw s, robust
ivregress 2sls lnw (s = q4), robustWhat the numbers show: The OLS and IV estimates are surprisingly close. OLS gives approximately 7% per year; IV gives a similar or slightly higher estimate. The IV standard error is considerably larger.
Why: Two offsetting biases: ability bias pushes OLS upward, measurement error pushes OLS downward. IV corrects both simultaneously, and the net correction is small because the two biases approximately cancel.
What it teaches: Similar point estimates can mask very different sources of variation. The IV estimate has a cleaner causal interpretation because it isolates exogenous variation in schooling.
- First-stage F-statistics: Using
qob_clean.csv, compute the first-stage F-statistic for Q4 alone and for all three quarter dummies (Q2, Q3, Q4) together. Do both exceed the “rule of 10” threshold? What does this tell you about instrument relevance?
NoteShow answer
Code
# --- Single Instrument: Q4 only ---
fs_q4_solo = pf.feols("s ~ q4", data=qob)
f_q4_solo = fs_q4_solo.tstat()['q4'] ** 2 # F = t² for single restriction
# --- Multiple Instruments: Q2 + Q3 + Q4 ---
fs_multi_solo = pf.feols("s ~ q2 + q3 + q4", data=qob)
# Joint F-test for multiple instruments (Wald test)
coefs_m = np.array([fs_multi_solo.coef()['q2'], fs_multi_solo.coef()['q3'], fs_multi_solo.coef()['q4']])
idx_m = [list(fs_multi_solo.coef().index).index(v) for v in ['q2', 'q3', 'q4']]
V_m = fs_multi_solo._vcov[np.ix_(idx_m, idx_m)]
f_multi_solo = float(coefs_m @ np.linalg.inv(V_m) @ coefs_m / 3)
pd.DataFrame({
"First stage": ["s ~ q4 (single)", "s ~ q2 + q3 + q4 (multiple)"],
"F-statistic": [round(f_q4_solo, 1), round(f_multi_solo, 1)],
"Exceeds rule of 10?": ["Yes" if f_q4_solo > 10 else "No",
"Yes" if f_multi_solo > 10 else "No"],
"N instruments": [1, 3],
})| First stage | F-statistic | Exceeds rule of 10? | N instruments | |
|---|---|---|---|---|
| 0 | s ~ q4 (single) | 48.1 | Yes | 1 |
| 1 | s ~ q2 + q3 + q4 (multiple) | 34.0 | Yes | 3 |
Stata equivalent:
* --- First-stage F-statistics ---
clear all
set more off
import delimited using "https://raw.githubusercontent.com/cmg777/intro2causal/main/data/ch6/qob_clean.csv", clear
reg s q4, robust
test q4
reg s q2 q3 q4, robust
test q2 q3 q4What the numbers show: Both F-statistics should exceed the “rule of 10” threshold, confirming that quarter of birth is a relevant instrument for schooling.
Why: Students born in Q4 enter school at a younger age, so by the time they reach the legal dropout age (e.g., 16), they have completed more years of schooling than those born in Q1, creating a systematic relationship between quarter of birth and years of schooling.
What it teaches: The first-stage F-statistic is the primary diagnostic for weak instruments. When F < 10, the IV estimate is biased toward OLS and standard errors are unreliable.
- Pre-trend test: Using
synthetic_did.csv, run the DD regression on only the pre-reform period (years before 2005). Is thetreat_postinteraction significant? What does this tell you about the parallel trends assumption?
NoteShow answer
Code
did = pd.read_csv(GITHUB_DATA_URL + "ch6/synthetic_did.csv")
pre = did[did["year"] < 2005].copy()
pre["placebo_post"] = (pre["year"] >= 2000).astype(int)
pre["placebo_treat_post"] = pre["treated"] * pre["placebo_post"]
placebo_dd = pf.feols("avg_earnings ~ placebo_treat_post | state + year", data=pre, vcov={"CRV1": "state"})
pd.DataFrame({
"Test": ["Placebo DD (pre-reform only, fake reform at 2000)"],
"Coefficient": [f"{placebo_dd.coef()['placebo_treat_post']:.4f}"],
"SE": [f"{placebo_dd.se()['placebo_treat_post']:.4f}"],
"p-value": [f"{placebo_dd.pvalue()['placebo_treat_post']:.3f}"],
})| Test | Coefficient | SE | p-value | |
|---|---|---|---|---|
| 0 | Placebo DD (pre-reform only, fake reform at 2000) | 0.0089 | 0.0111 | 0.433 |
If the placebo coefficient is small and insignificant, the parallel trends assumption is supported.